
Python & Pandas:构造lambda参数
我正在用Python和Pandas编写一个脚本,它使用lambda语句在csv列中根据分配给每一行的数字等级编写预先格式化的注释。虽然我可以做一些系列,但我有困难的一个案例。
这里是csv的is结构:

下面是编写新列composition_comment的工作代码。(我确信有一种更简洁的表达方式,但我仍然在学习Python和Pandas。)
import pandas as pd
df = pd.read_csv('stack.csv')
composition_score_value = 40 #calculated by another process
composition_comment_a_level = "Good work." # For scores falling between 100 and 90 percent of composition_score_value.
composition_comment_b_level = "Satisfactory work." # For scores between 89 and 80.
composition_comment_c_level = "Improvement needed." # For scores between 79 and 70.
composition_comment_d_level = "Unsatisfactory work." # For scores below 69.
df['composition_comment'] = df['composition_score'].apply(lambda element: composition_comment_a_level if element <= (composition_score_value * 1) else element >= (composition_score_value *.90))
df['composition_comment'] = df['composition_score'].apply(lambda element: composition_comment_b_level if element <= (composition_score_value *.899) else element >= (composition_score_value *.80))
df['composition_comment'] = df['composition_score'].apply(lambda element: composition_comment_c_level if element <= (composition_score_value *.799) else element >= (composition_score_value *.70))
df['composition_comment'] = df['composition_score'].apply(lambda element: composition_comment_d_level if element <= (composition_score_value *.699) else element >= (composition_score_value *.001))
df
df.to_csv('stack.csv', index=False)预期产出如下:
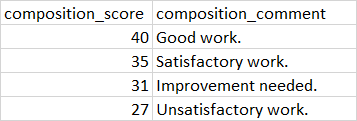
但实际产出是:
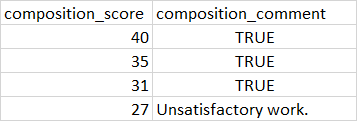
对于为什么要编写True值,以及为什么最后一行处理正确,有什么想法吗?任何帮助都很感激。
回答 5
Stack Overflow用户
发布于 2021-07-28 14:57:11
虽然许多其他选项显示了如何改进apply操作,但我建议使用pd.cut
df['composition_comment'] = pd.cut(
df['composition_score'] / composition_score_value, # Divide to get percent
bins=[0, 0.7, 0.8, 0.9, np.inf], # Set Bounds
labels=[composition_comment_d_level, # Set Labels
composition_comment_c_level,
composition_comment_b_level,
composition_comment_a_level],
right=False # Set Lower bound inclusive
)df
composition_score composition_comment
0 40 Good work.
1 35 Satisfactory work.
2 31 Improvement needed.
3 27 Unsatisfactory work.*设置right=False使低界包含,这意味着回收箱是:
[0.0, 0.7) # 0.0 (inclusive) up to 0.7 (not inclusive)
[0.7, 0.8) # 0.7 (inclusive) up to 0.8 (not inclusive)
[0.8, 0.9) # 0.8 (inclusive) up to 0.9 (not inclusive)
[0.9, inf) # 0.9 (inclusive) up to infinity备注:
如果有一个集合上界,可以修改
inf。如果小于0的值是预期的1.np.NINF,则1将不作为right=False的上限工作,因为1严格地不小于
可以使用的值而不是下限。
主要的好处是,有一个明确的,这是返回。这意味着像sort_values这样的操作将排序,而不是按字母顺序排序,而是按类别排序。
['Unsatisfactory work.' < 'Improvement needed.' < 'Satisfactory work.' < 'Good work.']df = df.sort_values('composition_comment')df
composition_score composition_comment
3 27 Unsatisfactory work.
2 31 Improvement needed.
1 35 Satisfactory work.
0 40 Good work.程序设置:
import numpy as np
import pandas as pd
df = pd.DataFrame({'composition_score': [40, 35, 31, 27]})
composition_score_value = 40 # calculated by another process
# For scores falling between 100 and 90 percent of composition_score_value.
composition_comment_a_level = "Good work."
# For scores between 89 and 80.
composition_comment_b_level = "Satisfactory work."
# For scores between 79 and 70.
composition_comment_c_level = "Improvement needed."
# For Scores below 70
composition_comment_d_level = "Unsatisfactory work."Stack Overflow用户
发布于 2021-07-28 14:52:06
它覆盖了您在以上代码行中所做的工作。当它看到满足element <= (composition_score_value *.699)的值时,它返回composition_comment_d_level。如果值不满足这一要求,则返回element >= (composition_score_value *.001),它本质上是一个布尔值,为True或False。
这一项应能发挥作用:
def composition_comment(element):
composition_score_value = 40
if element <= (composition_score_value *.699) :
return "Unsatisfactory work."
elif element <= (composition_score_value *.799):
return "Improvement needed."
elif element <= (composition_score_value *.899):
return "Satisfactory work."
elif element <= (composition_score_value * 1):
return "Good work."
else:
return None
df['composition_comment'] = df['composition_score'].apply(composition_comment)
dfStack Overflow用户
发布于 2021-07-28 14:55:05
您可以使用pd.cut()来执行映射,这比在if-else语句中显式写出每个条件要好得多:
import pandas as pd
df = pd.DataFrame({'composition_score': [40, 35, 31, 27]})
composition_score_value = 40
bins = pd.IntervalIndex.from_tuples([(0, 70), (70,80), (80,90), (90,100)])
labels = ['Unsatisfactory work.','Improvement needed.','Satisfactory work.','Good work.']
d = dict(zip(bins,labels))
x = pd.cut(df['composition_score']/composition_score_value*100, bins, right=False).map(d)产量:
0 Good work.
1 Satisfactory work.
2 Improvement needed.
3 Unsatisfactory work.
Name: composition_score, dtype: category
Categories (4, object): ['Unsatisfactory work.' < 'Improvement needed.' < 'Satisfactory work.' < 'Good work.']https://stackoverflow.com/questions/68562357
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号