
Pytorch C++ (Libtroch),使用互操作并行
我正在使用C++ API of PyTorch (libtorch)开发一个机器学习系统。
最近我一直在研究libtorch的性能、CPU利用率和GPU的使用情况。通过我的研究,我知道Torch在CPU上使用了两种并行化方法:
inter-op并行化intra-op并行化
我的主要问题是
- 这两者的区别
- 如何利用
inter-op并行
我知道,我可以使用intra-op函数指定用于openmp并行性的线程数(据我理解使用openmp后端执行),在监视模型的性能时,我可以清楚地看到它利用了我使用该函数指定的线程数,并且通过更改intra-op线程数可以清楚地看到性能上的差异。
还有另一个函数torch::set_num_interop_threads(),但是不管我指定了多少个互操作线程,我都看不到性能上的任何差异。
现在我已经读过这篇PyTorch文档文章了,但我仍然不清楚如何使用inter线程池。
医生说:
PyTorch使用单个线程池进行互操作并行,这个线程池由应用程序进程中的所有推理任务共享。
我有两个问题要问这个部分:
- 我是否需要自己创建新线程来利用
interop线程,还是torch在内部为我创建了新线程? - 如果我需要自己创建新线程,那么如何在C++中创建新线程,以便从
interop线程池中创建一个新线程?
在python示例中,他们使用来自torch.jit模块的fork函数,但我在C++ API中找不到类似的东西。
回答 1
Stack Overflow用户
发布于 2021-07-13 12:42:25
问题
这两者的区别
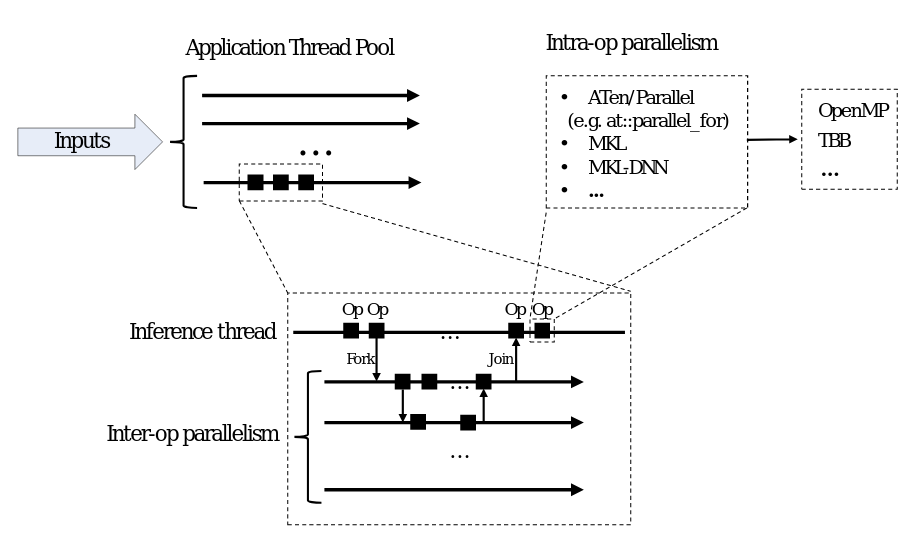
从这张照片上可以看出:
intra-op-为单个操作(如matmul或任何其他“每个张量”)执行的并行化inter-op-您有多个操作,它们的计算可以交织在一起。
inter-op“示例”:
op1启动并返回“未来”对象(一旦操作完成,我们就可以查询结果的对象)op2在之后立即启动(因为op1现在是非阻塞的)op2饰面- 我们可以查询
op1的结果(希望已经完成,或者至少更接近完成) - 我们将
op1和op2结果相加在一起(或者我们想用它们做什么)
由于上述原因:
intra-op工作时不添加任何内容(就像PyTorch处理的那样),并且应该提高性能inter-op是用户驱动的(特别是模型的体系结构,尤其是forward),因此必须考虑到!来创建体系结构。
如何利用互操作并行性?
除非您考虑使用inter-op来构建模型(例如使用Futures,请参阅您发布的链接中的第一个代码片段),否则您不会看到任何性能改进。
最有可能是
- 您的模型是用Python编写的,转换为
torchscript,只有推理是用C++完成的。 - 您应该用Python编写(或重构现有的)
inter-op代码,例如使用torch.jit.fork和torch.jit.wait
我是否需要自己创建新线程来利用互操作线程,或者火炬是否在内部为我创建了新线程?
不确定目前在C++中是否可行,无法找到任何torch::jit::fork或相关功能。
如果我需要自己创建新线程,我如何在C++中这样做,以便创建一个新线程形成互操作线程池?
虽然C++的API的目标不太可能是模仿Python的API尽可能接近现实。您可能需要更深入地挖掘与它相关的源代码和/或在他们的GitHub回购上发布一个特性请求(如果需要的话)。
https://stackoverflow.com/questions/68361267
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号