
试图刮掉市场份额,得到“零”
试图刮掉市场份额,得到“零”
提问于 2021-07-01 14:18:14
我用python构建了一个基本脚本,用于、、coinmarketcap帽中的一些数据,但我没有得到,我也不知道为什么,你能帮我吗?
from bs4 import BeautifulSoup as S
import requests
c = input('enter your coin')
url = f'https://coinmarketcap.com/currencies/{c}/'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
r = requests.get(url,headers=headers)
soup = S(r.content,'html.parser')
print(f'the price of {c} now is ')
x = soup.find(id="priceValue___11gHJ")
print(x)```回答 1
Stack Overflow用户
发布于 2021-07-01 14:58:14
我已经测试了您的代码,并进行了一些更改以使其工作。
要获得的字段使用类而不是id。
看一看。
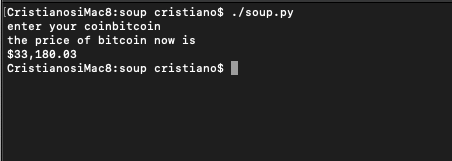
#!/usr/bin/env python3
from bs4 import BeautifulSoup as S
import requests
c = input('enter your coin')
url = f'https://coinmarketcap.com/currencies/{c}/'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
r = requests.get(url,headers=headers)
soup = S(r.content,'html.parser')
print(f'the price of {c} now is ')
x = soup.find(class_='priceValue___11gHJ').text
print(x)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68211892
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号