
如何更改我的代码中的for循环,以便在我的dataframe中给出一个额外的列?
如何更改我的代码中的for循环,以便在我的dataframe中给出一个额外的列?
提问于 2021-06-04 00:57:19
我正在进行语义搜索,以在两个文本列中找到最近的同义词,在两个不同的数据格式中查找。
代码如下,
"""
This is a simple application for sentence embeddings: semantic search
We have a corpus with various sentences. Then, for a given query sentence,
we want to find the most similar sentence in this corpus.
This script outputs for various queries the top 5 most similar sentences in the corpus.
"""
from sentence_transformers import SentenceTransformer, util
import torch
embedder = SentenceTransformer('paraphrase-distilroberta-base-v1')
# Corpus with example sentences
corpus = ind_type_new['Industry_type_new_list'].to_list()
corpus_embeddings = embedder.encode(corpus, convert_to_tensor=True)
# Query sentences:
queries = df_test['industry_types_test'][df_test['industry_types_test'] != ''].head(50)
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(1, len(corpus))
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
cos_scores = util.pytorch_cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print("\n\n======================\n\n")
print("Query:", query)
print("\nTop 5 most similar sentences in corpus:")
for score, idx in zip(top_results[0], top_results[1]):
print(corpus[idx], "(Score: {:.4f})".format(score))代码的输出如下所示
======================
Query: Farming
Top 5 most similar sentences in corpus:
Agriculture (Score: 0.4851)
Construction (Score: 0.4436)
Manufacturing (Score: 0.4099)
Property (Score: 0.3876)
Importer (Score: 0.3616)
======================
Query: Shopping Centre
Top 5 most similar sentences in corpus:
Consumer Services (Score: 0.4105)
Hospitality (Score: 0.4089)
Business Services (Score: 0.3898)
Wholesale / Distribution (Score: 0.3863)
Retail (Score: 0.3625)
======================
Query: Retail Food
Top 5 most similar sentences in corpus:
Retail (Score: 0.7708)
Consumer Services (Score: 0.4168)
Accommodation and Food Services (Score: 0.4085)
Business Services (Score: 0.3977)
Insurance (Score: 0.3870)正如你所看到的,它给出了前5个最好的分数,我希望文本与前1最好的分数,它应该是一个额外的列在我的数据df_test。我应该做什么改变?
我试过了
top_k=1 #because we only want the top match
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
cos_scores = util.pytorch_cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
df_test.at[query, "Match"] = corpus[int(top_results[1])] #save the result to your df这确实给了我一个“匹配”列,但它的所有NaN值。只有当其余的数据文件为空时,才不是NaN。
示例输出应该如下所示
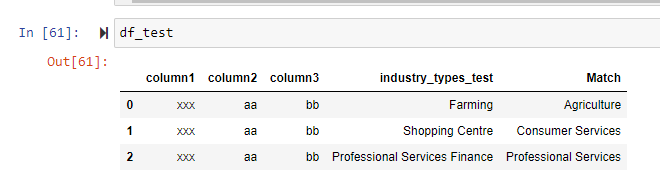
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-06-04 02:51:33
我从来没有使用过py手电筒,但我假设您可以得到每个查询的最大分数,然后再打印出来。
top_k = min(1, len(corpus))
top_industries = []
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
cos_scores = util.pytorch_cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
max_score = max(zip(top_results[0], top_results[1]), key=lambda s:s[0])
top_industries.append(corpus[max_score[1]])
df_test = df_test.assign(Match=pd.Series(top_industries))打印max_score应返回列中最佳匹配的同义词。
您只需通过DataFrame.assign()和Series()添加一个新列即可。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67830232
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号