
我是否可以修改一个数据表以匹配另一个数据帧的ID,这些ID几乎是相似的?
我有多个数据帧要比较。我的问题是产品ID。其中一个设置如下:
- 千万万
- Vs
- 千-万
(毛额)
我看过这里,reddit,YouTube,甚至深入到兔子洞的深处去尝试.join,.append,一些我以前从未见过,甚至还没有理解过的方法。是否有一种方法(或者更好的一些我可以阅读的文档来学习这一点)从主excel表中提取产品ID,并将其与应该匹配的产品ID进行比较。然后,我会更喜欢在所有床单的位置ID。这样,我可以使用这些ID作为索引,并并行比较ID行数据吗?每个ID大约有113个值要比较。这是113列,但对于每一行,如果这是有意义的
示例:(彩色列是将与之比较的非彩色列的主表)
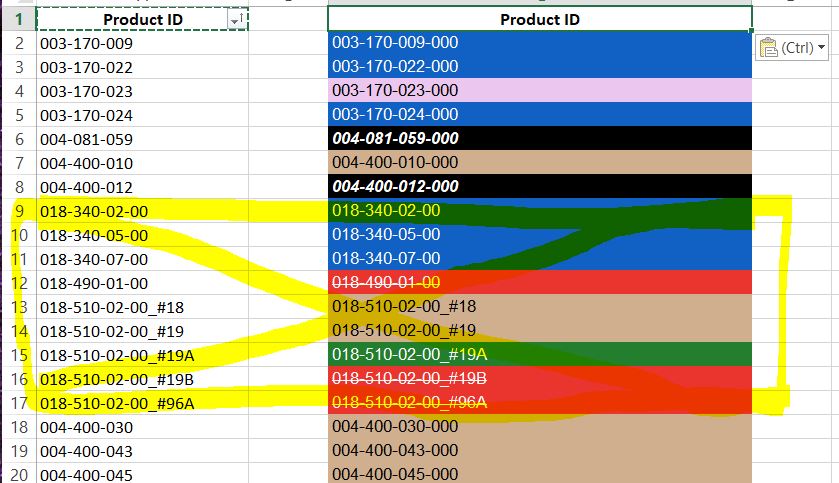
附加注意事项:突出显示的黄色if是“唯一的”,我不会更改它们,而是将它们写到列表或其他东西中,并在找到时使用if语句忽略它们。
编辑:所以我写了这段代码,这几乎是我需要做的事情。它去掉了我所有身份证上的"-“。只需列出唯一的ID列表,就可以在取零时跳过。
dfSS["Product ID"] = dfSS["Product ID"].str.replace("-", "")然后,这将只列出不超过9位的数字,唯一的ID除外。
dfSS["Product ID"] = dfSS["Product ID"]str[:9]一旦我使它100%工作,将在这里添加完整的代码。
我现在想弄清楚该怎么说
lst =[1,2,3,4,5]
if dfSS["Product ID"] not in lst:
dfSS["Product ID"] = dfSS["Product ID"].str.replace("-", "").str[:9]这段代码不起作用,但每天我都越来越接近于能够比较这些相似但不同的数据框架。lst只是我根本不想过滤的列表中1000000000个产品I的一个例子。但是保持在数据框架内
回答 2
Stack Overflow用户
发布于 2021-05-21 05:43:55
如果ID转换是可预测的,那么一个选项是使用regex对ID进行均匀化。例如,如果情况只是删除前三位数字,则可以使用以下内容:
df['short_id'] = df['long_id'].str.extract(r'\d\d\d-([\d-]*)')如果ID转换不是那么可预测的(例如,由于数据中的转录错误或其他噪声),那么最好的选择是首先使用类似recordlinkage的方法消除ID转换的歧义,参见示例这里。
Stack Overflow用户
发布于 2021-06-17 20:57:54
好的,对于每一个有或没有破折号、#、ltters等等的产品ID,都解决了这个问题。
(\d\d\d-)?[_#\d-]?[a-zA-Z]?(\d\d-)?-This用于第一个和第二个整数集、w/零或多个匹配和一个破折号(非贪婪)
_#\d-?-这是用于任何特殊字符和附加数字(非贪婪)
A-zA?-这个,不知道为什么,但我不得不从最后一部分分开,因为它不会把每封信都捡起来。(非贪婪)
有了以上这些,我解决了所有我需要的RE。
在那里我学会了如何提高我的可再生能源技能:
更多的方法来证明这一点。把这个放在这里是为了表明没有一种方法可以做到。RE是超级棒:
(\d{3}-)?[_#\d{3}-]?[a-zA-Z]?https://stackoverflow.com/questions/67630657
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号