
了解作为实现如何将Gram-Schmidt过程转换为这段代码。
了解作为实现如何将Gram-Schmidt过程转换为这段代码。
提问于 2021-05-20 10:22:16
试图从这个解释中理解格拉姆-施密特过程:
http://mlwiki.org/index.php/Gram-Schmidt_Process
计算的步骤对我来说是有意义的。但是,在同一篇文章中包含的Python实现似乎没有对齐。
def normalize(v):
return v / np.sqrt(v.dot(v))
n = len(A)
A[:, 0] = normalize(A[:, 0])
for i in range(1, n):
Ai = A[:, i]
for j in range(0, i):
Aj = A[:, j]
t = Ai.dot(Aj)
Ai = Ai - t * Aj
A[:, i] = normalize(Ai)从上面的代码中,我们可以看到它为和b做了点积,但是( V1,V1)部分并不是分母(参见下面的公式)。我想知道下面的方程是如何转换成驻留在for循环中的代码的?
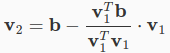
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-05-26 01:36:26
这正是代码所做的。
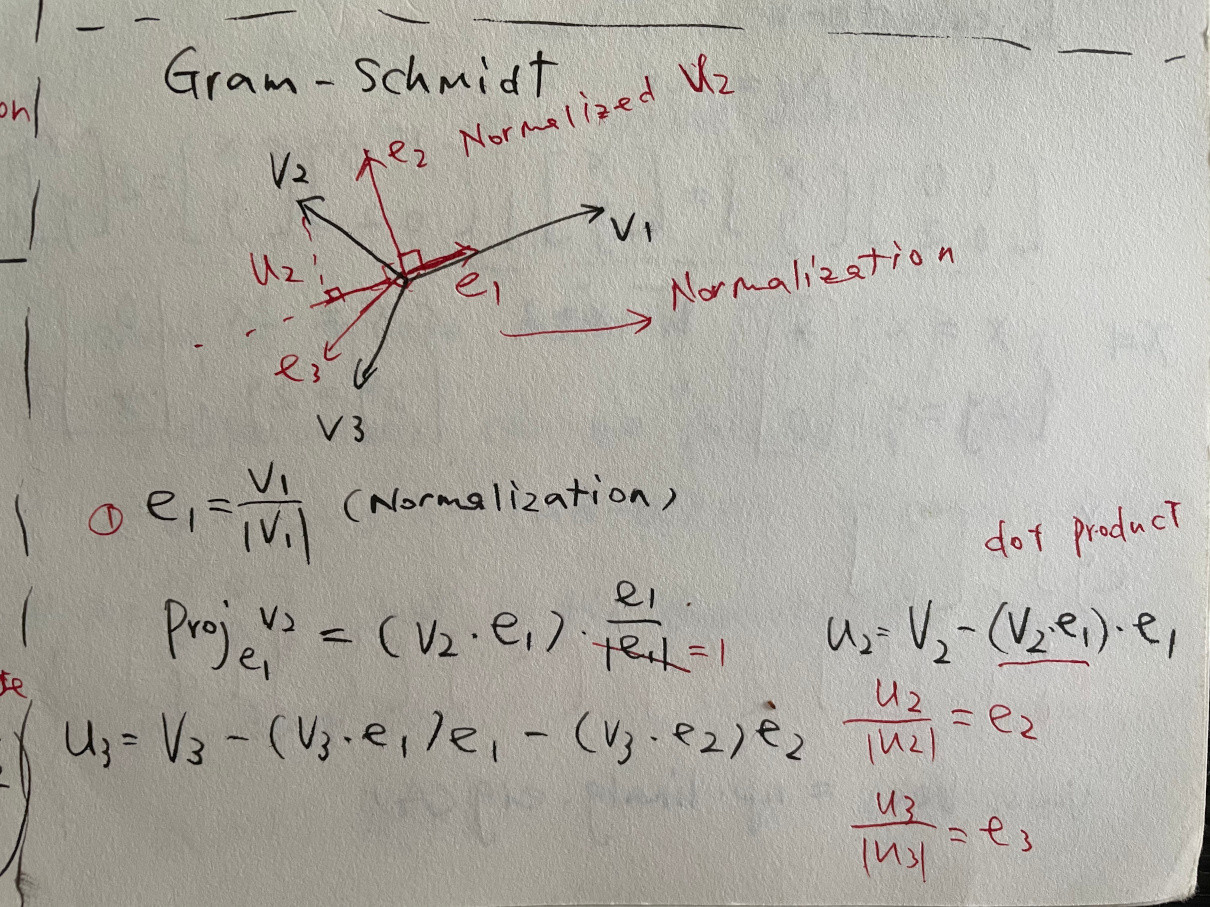
基本上,它规范了以前的向量(A中的列),并将当前的向量投影到它,并由当前的向量减去。
每一个向量都要进行归一化,以便进行简洁的计算。
上面的V2方程没有对前一个向量进行规范化,因此产生了差异。
Stack Overflow用户
发布于 2021-12-29 10:45:19
尝试这个向量化的实现。
另外,我建议阅读大卫·C的理论书籍。
def replace_zero(array):
for i in range(len(array)) :
if array[i] == 0 :
array[i] = 1
return arraydef gram_schmidt(self,A, norm=True, row_vect=False):
"""Orthonormalizes vectors by gram-schmidt process
Parameters
-----------
A : ndarray,
Matrix having vectors in its columns
norm : bool,
Do you need Normalized vectors?
row_vect: bool,
Does Matrix A has vectors in its rows?
Returns
-------
G : ndarray,
Matrix of orthogonal vectors
Gram-Schmidt Process
--------------------
The Gram–Schmidt process is a simple algorithm for
producing an orthogonal or orthonormal basis for any
nonzero subspace of Rn.
Given a basis {x1,....,xp} for a nonzero subspace W of Rn,
define
v1 = x1
v2 = x2 - (x2.v1/v1.v1) * v1
v3 = x3 - (x3.v1/v1.v1) * v1 - (x3.v2/v2.v2) * v2
.
.
.
vp = xp - (xp.v1/v1.v1) * v1 - (xp.v2/v2.v2) * v2 - .......
.... - (xp.v(p-1) / v(p-1).v(p-1) ) * v(p-1)
Then {v1,.....,vp} is an orthogonal basis for W .
In addition,
Span {v1,.....,vp} = Span {x1,.....,xp} for 1 <= k <= p
References
----------
Linear Algebra and Its Applications - By David.C.Lay
"""
if row_vect :
# if true, transpose it to make column vector matrix
A = A.T
no_of_vectors = A.shape[1]
G = A[:,0:1].copy() # copy the first vector in matrix
# 0:1 is done to to be consistent with dimensions - [[1,2,3]]
# iterate from 2nd vector to number of vectors
for i in range(1,no_of_vectors):
# calculates weights(coefficents) for every vector in G
numerator = A[:,i].dot(G)
denominator = np.diag(np.dot(G.T,G)) #to get elements in diagonal
weights = np.squeeze(numerator/denominator)
# projected vector onto subspace G
projected_vector = np.sum(weights * G,
axis=1,
keepdims=True)
# orthogonal vector to subspace G
orthogonalized_vector = A[:,i:i+1] - projected_vector
# now add the orthogonal vector to our set
G = np.hstack((G,orthogonalized_vector))
if norm :
# to get orthoNormal vectors (unit orthogonal vectors)
# replace zero to 1 to deal with division by 0 if matrix has 0 vector
# or normazalization value comes out to be zero
G = G/self.replace_zero(np.linalg.norm(G,axis=0))
if row_vect:
return G.T
return GG = np.array([[1,0,0],[1,1,0],[1,1,1],[1,1,1]])
gram_schmidt(G)
>
array([[ 0.5 , -0.8660254 , 0. ],
[ 0.5 , 0.28867513, -0.81649658],
[ 0.5 , 0.28867513, 0.40824829],
[ 0.5 , 0.28867513, 0.40824829]])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67618474
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号