
NLP ELMo模型剪枝输入
我试图根据tensorflow集线器上可用的经过预先训练的ELMo模型检索单词的嵌入。我使用的代码是从这里修改的:https://www.geeksforgeeks.org/overview-of-word-embedding-using-embeddings-from-language-models-elmo/
我输入的句子是
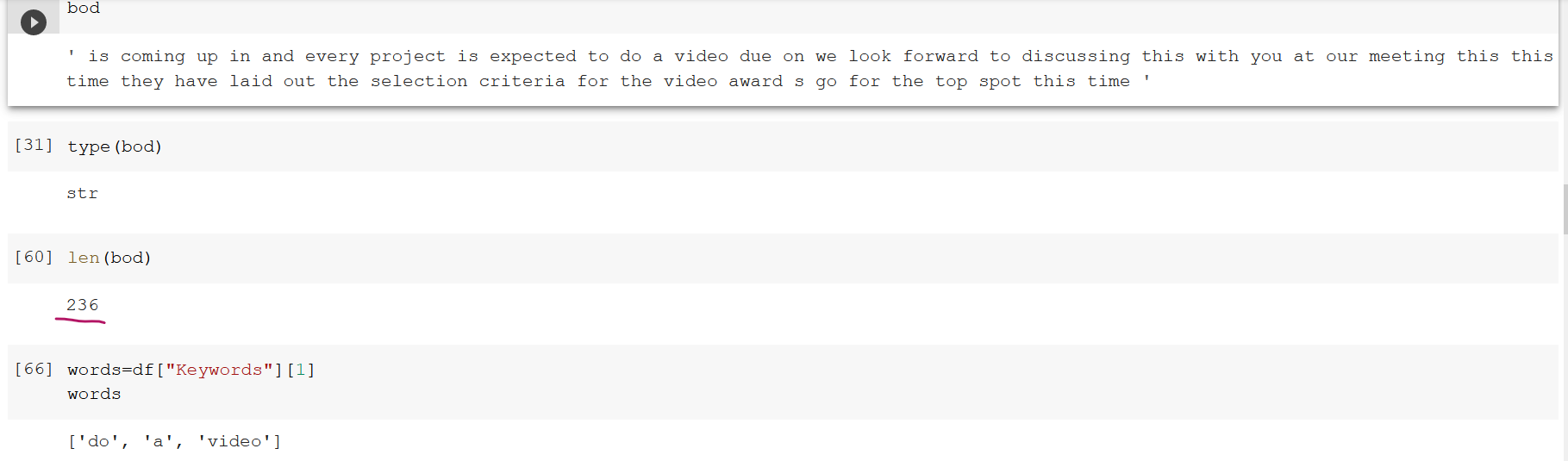
bod =“即将到来,每个项目都将制作一段视频,我们期待着在这次会议上与您讨论这个问题,这次他们已经制定了视频奖的选择标准,这一次我们将获得第一名。”
这些是我想要嵌入的关键字:
words="do“、"a”、“视频”
embeddings = elmo([bod],
signature="default",
as_dict=True)["elmo"]
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)这句话长236个字。这张照片显示
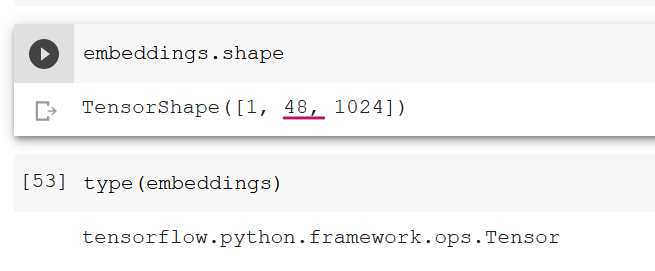
但是,当我将这个句子放入ELMo模型中时,返回的张量只包含一个长度为48的字符串。
当我试图提取超出48长度限制的关键字的嵌入时,这就变成了一个问题,因为关键字的索引显示超出了这个长度:

这是我用来获取“bod”中单词索引的代码(如上面所示)。
num_list=[]
for item in words:
print(item)
index = bod.index(item)
num_list.append(index)
num_list但我经常遇到这样的错误:
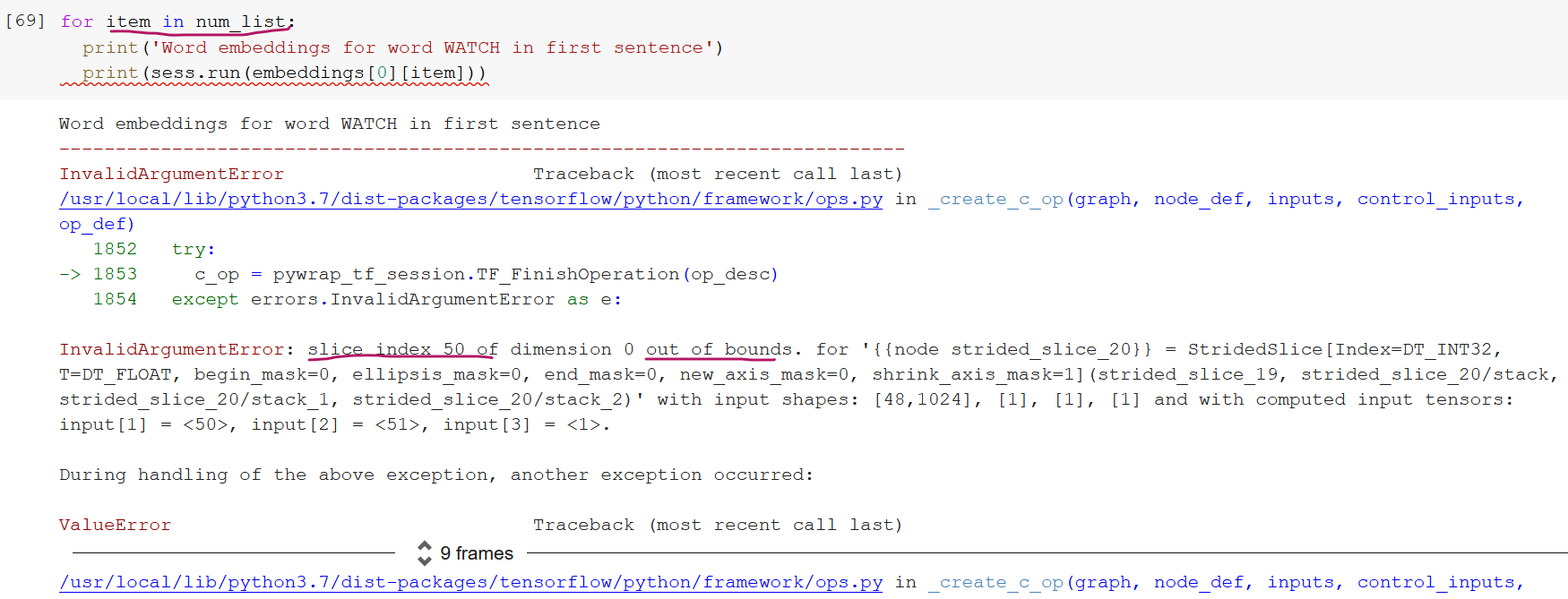
我试着寻找ELMo文档来解释为什么会发生这种情况,但是我没有发现任何与修剪输入的问题有关的东西。
任何建议都非常感谢!
谢谢
回答 1
Stack Overflow用户
发布于 2021-05-27 04:47:21
这实际上不是一个AllenNLP问题,因为您正在使用基于tensorflow的ELMo实现。
尽管如此,我认为问题在于ELMo嵌入的是令牌,而不是字符。您将得到48个嵌入,因为字符串有48个令牌。
https://stackoverflow.com/questions/67558874
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号