
如何在python中基于多个输入过滤值
如何在python中基于多个输入过滤值
提问于 2021-05-15 08:27:02
嗨,我已经开始做一个项目,在这个项目中,我需要根据下面的层次结构为底层选择最好的代理。
- Sector
- Region (CCY)
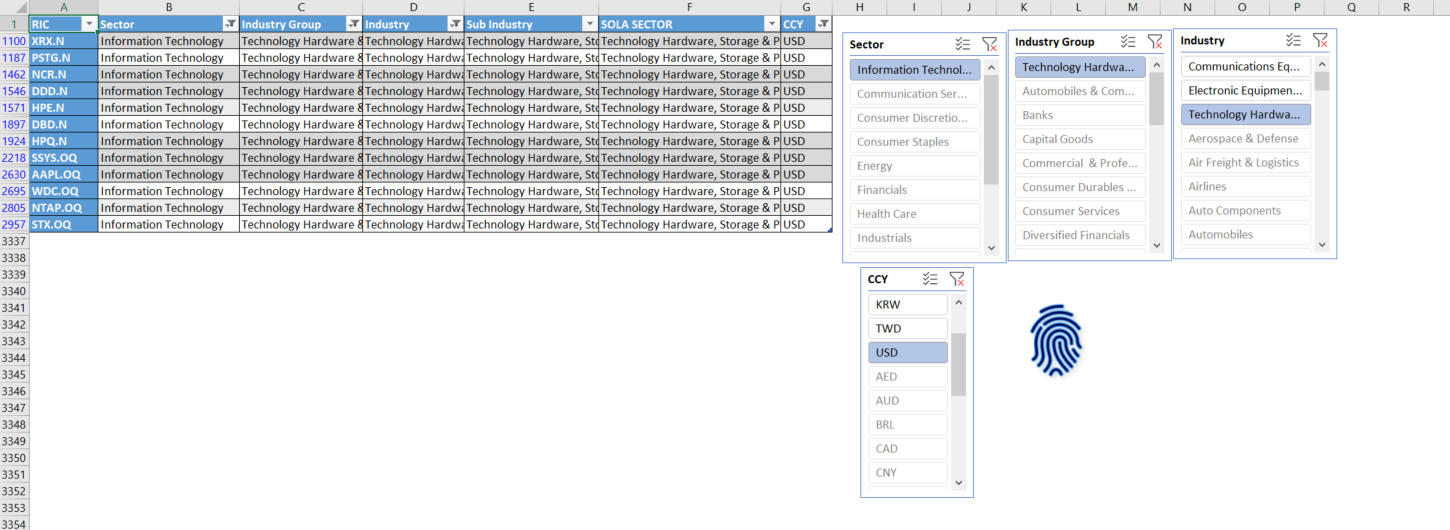
例如,我的想法是,如果我们想为UL AAPL.OQ找到一个合适的代理(部门:IT,工业集团:Technology Hardware,Indusry:Technology Hardware,Region (ccy):美元)
该工具应该过滤出保存在csv中的整个宇宙的信息,基于给定的输入类扇区、子扇区和区域的参数(如下面的屏幕截图所示),筛选出合适的代理列表。如果我们能在蟒蛇身上做同样的事呢?此外,我们如何在同一时间实现多个底层的这一目标?
import pandas as pd
import numpy as np
df = pd.read_csv('C:\\Users\\samuel\\Desktop\\Sector.csv')
df.columns = ['RIC','Sector','Industry Group','Sub Industry', 'SOLA SECTOR', 'CCY']
print(df)
filter_data = int(input('select sector: '))
filter_data = int(input('select region: '))
filtered=(df.loc[df['sector'] == filter_data])
indexdata = filtered.set_index(' ')
回答 1
Stack Overflow用户
发布于 2021-05-15 09:50:17
如果您正在寻找多个选择,则只需:
sector = int(input('select sector: '))
region = int(input('select region: '))
filtered=(df.loc[(df['sector'] == sector) &(df['region'] == region)])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67544724
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号