
需要计算顺序中的下一个里程碑
需要计算顺序中的下一个里程碑
提问于 2021-05-11 07:22:20
我有一个像这样的数据集
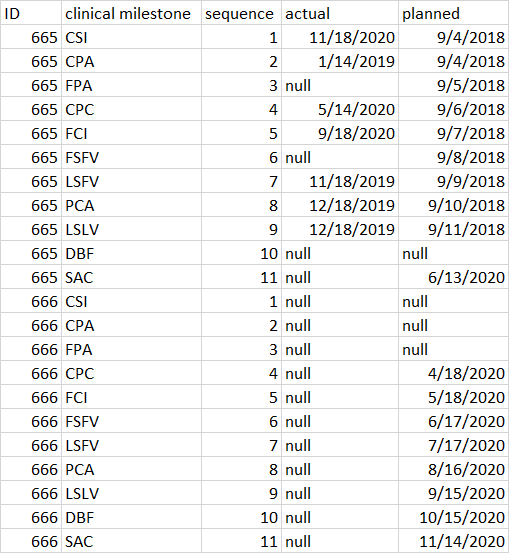
我想根据序列号为ID计算下一个临床里程碑。例如,对于665,根据序列,下一个临床里程碑应该是DBF,因为它在实际列中没有任何日期(我们需要忽略中间值,如FPA和FCI,在这些中间值中,数据不存在列实际,因为数据非常脏,日期可以相对于最后一列顺序更小)。
在另一种情况下,ID的实际列中的所有数据都为空,在这种情况下,该临床里程碑的第一个非空计划列值应该是下一个。
在ID 666中,CPC应该是下一个临床里程碑。
考虑到使用滞后函数,也使用最大值的实际ID,但不确定它将如何工作,当两行有相同的实际日期。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-05-11 07:26:59
使用MAX() OVER ()和一个CASE表达式计算每个id的当前序列值,然后在此基础上进行筛选。
WITH
resequenced AS
(
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY sequence) AS new_sequence
FROM
yourTable
WHERE
actual IS NOT NULL
OR planned IS NOT NULL
),
summarised AS
(
SELECT
*,
MAX(CASE WHEN actual IS NOT NULL THEN new_sequence ELSE 0 END) OVER (PARTITION BY id) AS last_sequence
FROM
resequenced
)
SELECT
*
FROM
summarised
WHERE
new_sequence = last_sequence + 1编辑:适应于处理actual和planned列中的空白。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67482209
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号