
Google对ASX数据失败
我正试图从https://finance.yahoo.com/中提取不同市场多家公司的“远期股利和收益”价值。
这是成功的:
=IMPORTXML("https://finance.yahoo.com/quote/WBS", "//*[@id='quote-summary']/div[2]/table/tbody/tr[6]/td[2]")但这对#N/A来说是失败的:
=IMPORTXML("https://finance.yahoo.com/quote/CBA.AX", "//*[@id='quote-summary']/div[2]/table/tbody/tr[6]/td[2]")我不知道ASX代码需要什么不同,为什么CBA.AX会导致问题?
非常感谢你的帮助
回答 2
Stack Overflow用户
发布于 2021-05-11 05:35:59
当我测试=IMPORTXML("https://finance.yahoo.com/quote/CBA.AX", "//*")公式时,Error Resource at url not found.出现了一个错误。我想这可能是你出问题的原因。
但是,幸运的是,当我尝试使用Google脚本从同一个URL检索HTML时,可以检索HTML。因此,在这个答案中,我建议使用Google脚本创建的自定义函数来检索值。示例脚本如下所示。
示例脚本:
请将以下脚本复制并粘贴到Google电子表格的脚本编辑器中并保存。请把=SAMPLE("https://finance.yahoo.com/quote/CBA.AX")的配方放进细胞里。这样,就可以检索该值。
function SAMPLE(url) {
const res = UrlFetchApp.fetch(url).getContentText().match(/DIVIDEND_AND_YIELD-value.+?>(.+?)</);
return res && res.length > 1 ? res[1] : "No value";
}结果:
当使用上述脚本时,将获得以下结果。
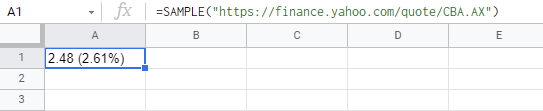
注意:
- 使用此脚本时,还可以使用
=SAMPLE("https://finance.yahoo.com/quote/WBS")。 - 在这种情况下,当更改URL的HTML结构时,可能无法使用此脚本。我认为
IMPORTXML和xpath的情况是一样的。所以请小心点。
参考文献:
Stack Overflow用户
发布于 2021-05-11 06:39:27
另一种解决方案是解码网页源中包含的json。当然,您不能使用importxml,因为web页面是由javascript构建的,而不是服务器端构建的。您可以通过这种方式访问数据并获取大量信息。
var source = UrlFetchApp.fetch(url).getContentText()
var jsonString = source.match(/(?<=root.App.main = ).*(?=}}}})/g) + '}}}}'也就是说,对于你正在寻找的东西,你可以使用
function trailingAnnualDividendRate(){
var url='https://finance.yahoo.com/quote/CBA.AX'
var source = UrlFetchApp.fetch(url).getContentText()
var jsonString = source.match(/(?<=root.App.main = ).*(?=}}}})/g) + '}}}}'
var data = JSON.parse(jsonString)
var dividendRate = data.context.dispatcher.stores.QuoteSummaryStore.summaryDetail.trailingAnnualDividendRate.raw
Logger.log(dividendRate)
}https://stackoverflow.com/questions/67480449
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号