
有什么更好的方法来聚合多个列在同一个分组的熊猫数据?
我试图弄清楚我应该如何操作我的数据,这样我就可以在多个列上聚合,但对于相同的分组熊猫数据。我这么做的原因是,我需要得到堆叠的线条图,它从同一分组数据上从不同的聚合中获取数据。我们怎么才能做到这一点呢?有人能提出在熊猫身上这样做的可能方法吗?有什么想法吗?
我目前的尝试
import pandas as pd
import matplotlib.pyplot as plt
url = "https://gist.githubusercontent.com/adamFlyn/4657714653398e9269263a7c8ad4bb8a/raw/fa6709a0c41888503509e569ace63606d2e5c2ff/mydf.csv"
df = pd.read_csv(url, parse_dates=['date'])
df_re = df[df['retail_item'].str.contains("GROUND BEEF")]
df_rei = df_re.groupby(['date', 'retail_item']).agg({'number_of_ads': 'sum'})
df_rei = df_rei.reset_index(level=[0,1])
df_rei['week'] = pd.DatetimeIndex(df_rei['date']).week
df_rei['year'] = pd.DatetimeIndex(df_rei['date']).year
df_rei['week'] = df_rei['date'].dt.strftime('%W').astype('uint8')
df_ret_df1 = df_rei.groupby(['retail_item', 'week'])['number_of_ads'].agg([max, min, 'mean']).stack().reset_index(level=[2]).rename(columns={'level_2': 'mm', 0: 'vals'}).reset_index()类似地,我需要进行数据聚合,如下所示:
df_re['price_gap'] = df_re['high_price'] - df_re['low_price']
dff_rei1 = df_re.groupby(['date', 'retail_item']).agg({'price_gap': 'mean'})
dff_rei1 = dff_rei1.reset_index(level=[0,1])
dff_rei1['week'] = pd.DatetimeIndex(dff_rei1['date']).week
dff_rei1['year'] = pd.DatetimeIndex(dff_rei1['date']).year
dff_rei1['week'] = dff_rei1['date'].dt.strftime('%W').astype('uint8')
dff_ret_df2 = dff_rei1.groupby(['retail_item', 'week'])['price_gap'].agg([max, min, 'mean']).stack().reset_index(level=[2]).rename(columns={'level_2': 'mm', 0: 'vals'}).reset_index()问题
当我进行数据聚合时,这些行类似:
df_rei = df_re.groupby(['date', 'retail_item']).agg({'number_of_ads': 'sum'})
df_ret_df1 = df_rei.groupby(['retail_item', 'week'])['number_of_ads'].agg([max, min, 'mean']).stack().reset_index(level=[2]).rename(columns={'level_2': 'mm', 0: 'vals'}).reset_index()和
dff_rei1 = df_re.groupby(['date', 'retail_item']).agg({'price_gap': 'mean'})
dff_ret_df2 = dff_rei1.groupby(['retail_item', 'week'])['price_gap'].agg([max, min, 'mean']).stack().reset_index(level=[2]).rename(columns={'level_2': 'mm', 0: 'vals'}).reset_index()我认为更好的方法可能是我必须使用*arg、**kwargs来定制函数,以便对列进行移位,但是我应该如何显示堆叠的线条图,其中y轴显示不同的数量。这在pandas中是可行的吗?
线图
我是为了得到线状图,如下所示:
for g, d in df_ret_df1.groupby('retail_item'):
fig, ax = plt.subplots(figsize=(7, 4), dpi=144)
sns.lineplot(x='week', y='vals', hue='mm', data=d,alpha=.8)
y1 = d[d.mm == 'max']
y2 = d[d.mm == 'min']
plt.fill_between(x=y1.week, y1=y1.vals, y2=y2.vals)
for year in df['year'].unique():
data = df_rei[(df_rei.date.dt.year == year) & (df_rei.retail_item == g)]
sns.lineplot(x='week', y='price_gap', ci=None, data=data, palette=cmap,label=year,alpha=.8)我希望将它们最小化,这样我就能够在不同的列上聚合,并生成叠加的直线图,其中它们共享x轴作为周,y轴分别显示ads和price_range的数量。我不知道有什么更好的方法可以做到这一点。我这样做是因为堆叠的线条图(两个垂直子图),一个显示y轴上的广告数量,另一个显示52周内相同项目的价格范围。有人能提出任何可行的方法吗?有什么想法吗?
回答 2
Stack Overflow用户
发布于 2021-05-09 21:00:13
这个答案建立在Andreas的回答之上,他已经回答了如何以紧凑的方式生成多列的聚合变量这一主要问题。这里的目标是具体针对您的情况实现该解决方案,并给出如何从聚合数据生成单个数字的示例。以下是一些要点:
- 原始数据集中的日期已经处于每周一次的频率上,因此
df_ret_df1和dff_ret_df2不需要使用groupby('week'),这就是为什么它们包含相同的min、max和mean值的原因。 - 示例使用熊猫和matplotlib,因此这些变量不需要像使用seaborn时那样堆叠。聚合步骤生成列的MultiIndex。您可以访问每个高级变量的聚合变量(最小、最大、平均),方法是将
df.xs. - The日期设置为聚合数据的索引,以用作x变量。使用DatetimeIndex作为x变量可以使您更灵活地格式化滴答标签,并确保数据总是按时间顺序绘制。
- 在问题中不清楚应如何显示不同年份的数据(以单独的数字显示?)在这里,整个时间序列用一个数字显示。
导入数据集并根据需要聚合数据集
import pandas as pd # v 1.2.3
import matplotlib.pyplot as plt # v 3.3.4
# Import dataset
url = 'https://gist.githubusercontent.com/adamFlyn/4657714653398e9269263a7c8ad4bb8a/\
raw/fa6709a0c41888503509e569ace63606d2e5c2ff/mydf.csv'
df = pd.read_csv(url, parse_dates=['date'])
# Create dataframe containing data for ground beef products, compute
# aggregate variables, and set the date as the index
df_gbeef = df[df['retail_item'].str.contains('GROUND BEEF')].copy()
df_gbeef['price_gap'] = df_gbeef['high_price'] - df_gbeef['low_price']
agg_dict = {'number_of_ads': [min, max, 'mean'],
'price_gap': [min, max, 'mean']}
df_gbeef_agg = (df_gbeef.groupby(['date', 'retail_item']).agg(agg_dict)
.reset_index('retail_item'))
df_gbeef_agg
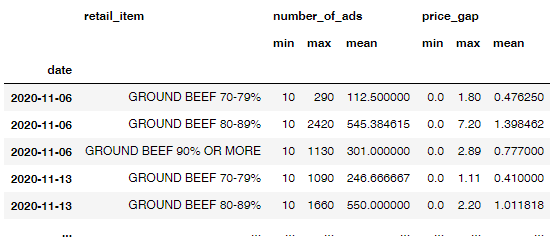
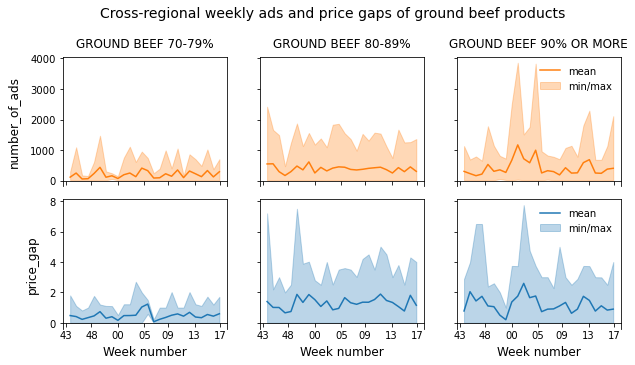
图中包含小倍数的单个图形中的聚集变量
variables = ['number_of_ads', 'price_gap']
colors = ['tab:orange', 'tab:blue']
nrows = len(variables)
ncols = df_gbeef_agg['retail_item'].nunique()
fig, axs = plt.subplots(nrows, ncols, figsize=(10, 5), sharex=True, sharey='row')
for axs_row, var, color in zip(axs, variables, colors):
for i, (item, df_item) in enumerate(df_gbeef_agg.groupby('retail_item')):
ax = axs_row[i]
# Select data and plot it
data = df_item.xs(var, axis=1)
ax.fill_between(x=data.index, y1=data['min'], y2=data['max'],
color=color, alpha=0.3, label='min/max')
ax.plot(data.index, data['mean'], color=color, label='mean')
ax.spines['bottom'].set_position('zero')
# Format x-axis tick labels
fmt = plt.matplotlib.dates.DateFormatter('%W') # is not equal to ISO week
ax.xaxis.set_major_formatter(fmt)
# Fomat subplot according to position within the figure
if ax.is_first_row():
ax.set_title(item, pad=10)
if ax.is_last_row():
ax.set_xlabel('Week number', size=12, labelpad=5)
if ax.is_first_col():
ax.set_ylabel(var, size=12, labelpad=10)
if ax.is_last_col():
ax.legend(frameon=False)
fig.suptitle('Cross-regional weekly ads and price gaps of ground beef products',
size=14, y=1.02)
fig.subplots_adjust(hspace=0.1);
Stack Overflow用户
发布于 2021-05-04 23:50:53
我不知道这是否完全回答了你的问题,但根据你的标题,我想这一切归结为:
import pandas as pd
url = "https://gist.githubusercontent.com/adamFlyn/4657714653398e9269263a7c8ad4bb8a/raw/fa6709a0c41888503509e569ace63606d2e5c2ff/mydf.csv"
df = pd.read_csv(url, parse_dates=['date'])
# define which columns to group and in which way
dct = {'low_price': [max, min],
'high_price': min,
'year': 'mean'}
# actually group the columns
df.groupby(['region']).agg(dct)输出:
low_price high_price year
max min min mean
region
ALASKA 16.99 1.33 1.33 2020.792123
HAWAII 12.99 1.33 1.33 2020.738318
MIDWEST 28.73 0.99 0.99 2020.690159
NORTHEAST 19.99 1.20 1.99 2020.709916
NORTHWEST 16.99 1.33 1.33 2020.736397
SOUTH CENTRAL 28.76 1.20 1.49 2020.700980
SOUTHEAST 21.99 1.33 1.48 2020.699655
SOUTHWEST 16.99 1.29 1.29 2020.704341https://stackoverflow.com/questions/67393421
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号