
提高大型JSON文件的读取性能
我不是一个IT工程师,但机械工程师,所以不要犹豫问我更多的细节。
我有大量的魔术收集卡,并写了一个程序,从图片通过OpenCV读取卡片。它处理图片,提取卡片的名称,在JSON文件中搜索它,并将它附加到我的库中。
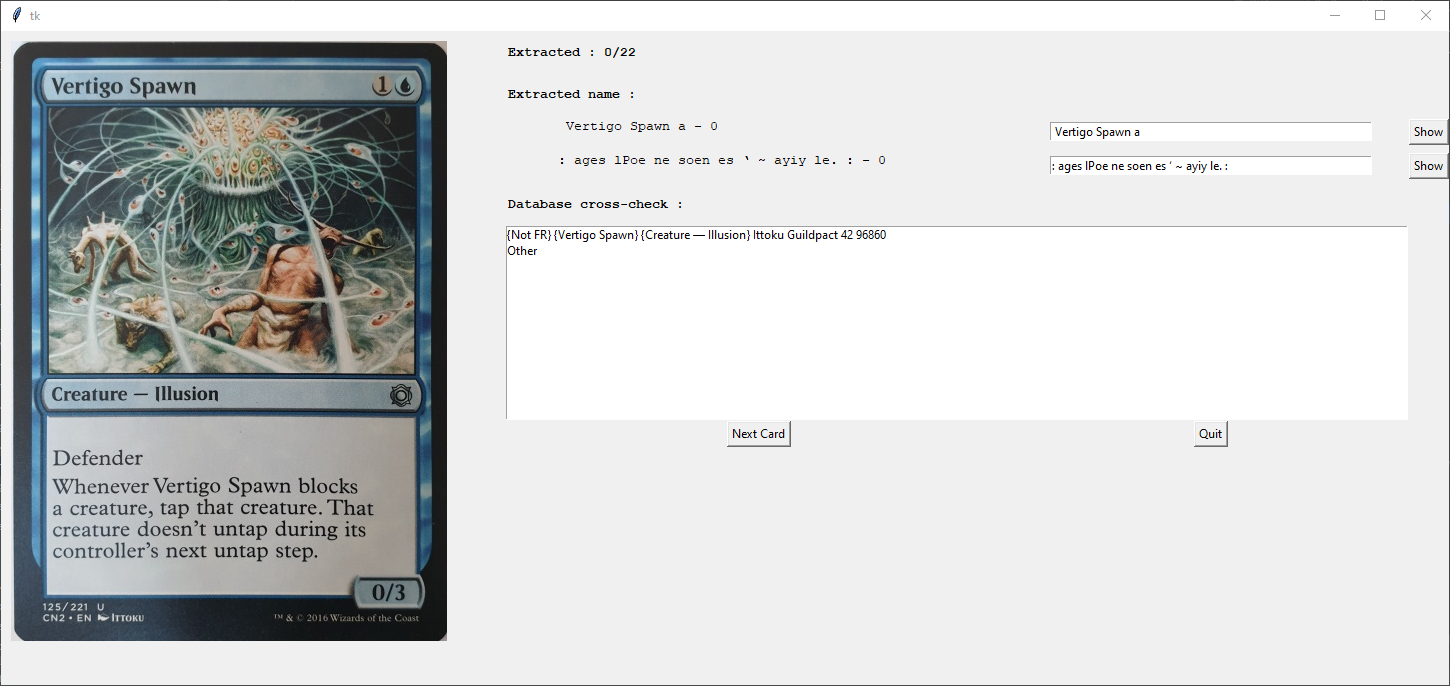
我试图优化JSON文件的读取,因为它会尽可能匹配图片中检测到的卡名。收集所有数据的Json文件大约为210 at,可在https://mtgjson.com/downloads/all-files/在线获取。
例如,考虑到变量"keyVal“中提取的卡名,大约需要10秒:
import json
from difflib import SequenceMatcher
def similar(a, b):
return SequenceMatcher(None, a, b).ratio()
keyVal ="Arc électrique"
json_file = open("AllPrintings.json", "r", encoding="utf-8")
bdd = json.load(json_file)
for item in bdd["data"]:
for card in bdd["data"][item]["cards"]:
for langue in card["foreignData"]:
if similar(langue["name"],keyVal) > 0.85:
print(langue["name"],card["name"], card["type"], card["artist"], bdd["data"][item]["name"], card["number"], card["identifiers"]["multiverseId"])
if similar(card["name"], keyVal) > 0.85:
print(card["name"], card["type"], card["artist"], bdd["data"][item]["name"],
card["number"], card["identifiers"]["multiverseId"])我的第一个意图是读取Json文件,只记录我需要的数据,但是它变成了一个非常大的文件……
你知道如何改善研究时间吗?
感谢并毫不犹豫地要求澄清。
回答 1
Stack Overflow用户
发布于 2021-04-15 09:15:22
我做了两件事是基于你回答@Tomalak。我使用sqlitebrowser创建并保存了sqlite中的专用表,该代码只包含我需要的数据:
CREATE table res AS SELECT
c.number, c.name, c.artist, fd.name AS local_name, fd.language, st.name as local_print
FROM
cards AS c
LEFT JOIN foreign_data AS fd ON fd.uuid = c.uuid
LEFT JOIN sets AS st ON st.code = c.setCode
WHERE
fd.language IS NULL OR fd.language = "French"然后,我在python中使用FTS4调用它,并连续执行两个请求来使用请求度量虚拟表初始化的时间,然后使用相同的虚拟化方式来度量单个请求的时间:
import sqlite3
import time
init = time.time()
keyVal ="Act of Treason"
conn = sqlite3.connect(r"AllPrintings.sqlite")
conn.create_function("SIMILAR", 2, similar)
cur = conn.cursor()
cur.execute('''DROP TABLE IF EXISTS mtgsearch''')
cur.execute('''CREATE VIRTUAL TABLE mtgsearch USING fts4(number, name, artist, namefr, language, local_print)''')
cur.execute('''INSERT INTO mtgsearch(number, name, artist, namefr, language, local_print) SELECT c.number AS number, c.name AS name, c.artist AS artist, c.local_name AS namefr, c.language AS language, c.local_print AS local_print FROM res AS c''')
conn.commit()
stock = cur.execute('''SELECT * FROM mtgsearch WHERE name= ?''',[keyVal])
for row in stock:
print(row[0], row[1], row[2], row[3], row[4], row[5])
print(time.time() - init)
init = time.time()
keyVal= "Air Elemental"
stock = cur.execute('''SELECT * FROM mtgsearch WHERE name= ?''',[keyVal])
for row in stock:
print(row[0], row[1], row[2], row[3], row[4], row[5])
print(time.time() - init)与以前的==>相比,结果是正念,第一次是0.4秒,第二次是0.015秒。
如果我使用Sequencematcher,第一次请求时间为1.7秒,第二次请求时间为1.3秒。因此,下一个目标是找到一种改进更快的相似算法的方法。有什么想法吗?
无论如何,谢谢你的帮助,我学到了很多关于SQLite的东西。我对写第一篇文章一无所知。
https://stackoverflow.com/questions/67054481
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号