
为什么它在使用存储在HDFS中的文件时说“(没有这样的文件或目录)”?
为什么它在使用存储在HDFS中的文件时说“(没有这样的文件或目录)”?
提问于 2021-04-04 15:47:32
所以我在HDFS上有这个文件,但是显然HDFS找不到它,我也不知道为什么。
我的代码是:
public static Schema getSchema() throws IOException {
InputStream is = new FileInputStream("hdfs:///schema.movies");
String ps = new String(is.readAllBytes());
MessageType mt = MessageTypeParser.parseMessageType(ps);
return new AvroSchemaConverter().convert(mt);
}在这里可以看到schema.movies文件:
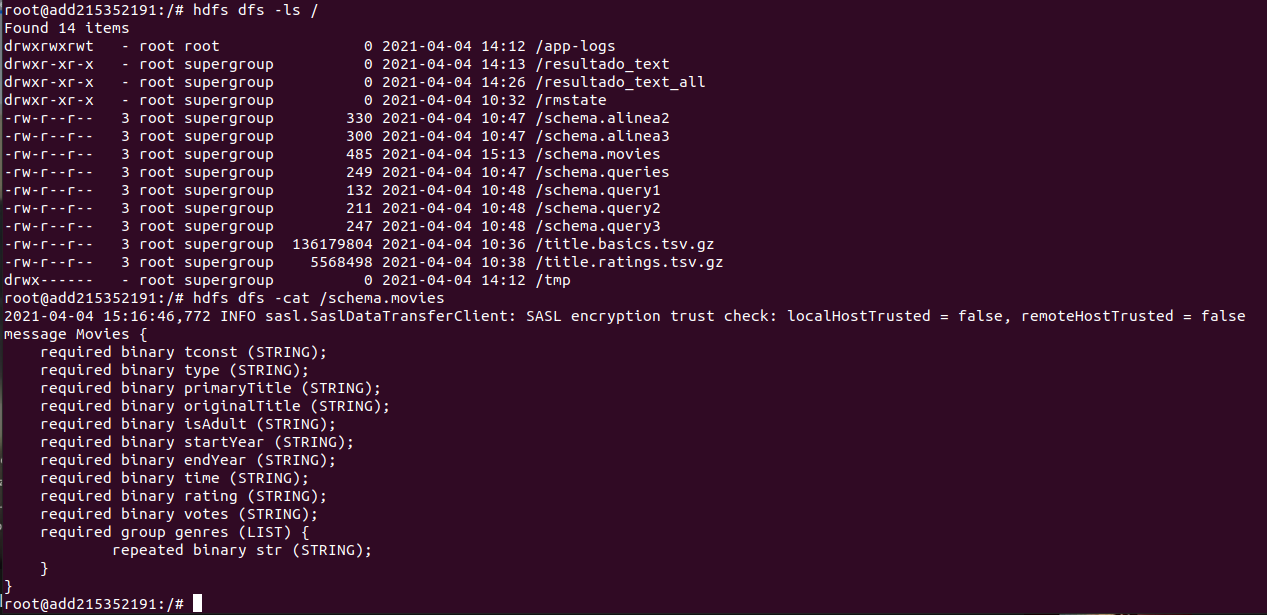
我得到的错误是:
Connected.
Configuring core
- Setting hadoop.proxyuser.hue.hosts=*
- Setting fs.defaultFS=hdfs://namenode:9000
- Setting hadoop.http.staticuser.user=root
- Setting io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec
- Setting hadoop.proxyuser.hue.groups=*
Configuring hdfs
- Setting dfs.namenode.datanode.registration.ip-hostname-check=false
- Setting dfs.webhdfs.enabled=true
- Setting dfs.permissions.enabled=false
Configuring yarn
- Setting yarn.timeline-service.enabled=true
- Setting yarn.scheduler.capacity.root.default.maximum-allocation-vcores=4
- Setting yarn.resourcemanager.system-metrics-publisher.enabled=true
- Setting yarn.resourcemanager.store.class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
- Setting yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage=98.5
- Setting yarn.log.server.url=http://historyserver:8188/applicationhistory/logs/
- Setting yarn.resourcemanager.fs.state-store.uri=/rmstate
- Setting yarn.timeline-service.generic-application-history.enabled=true
- Setting yarn.log-aggregation-enable=true
- Setting yarn.resourcemanager.hostname=resourcemanager
- Setting yarn.scheduler.capacity.root.default.maximum-allocation-mb=8192
- Setting yarn.nodemanager.aux-services=mapreduce_shuffle
- Setting yarn.resourcemanager.resource_tracker.address=resourcemanager:8031
- Setting yarn.timeline-service.hostname=historyserver
- Setting yarn.resourcemanager.scheduler.address=resourcemanager:8030
- Setting yarn.resourcemanager.address=resourcemanager:8032
- Setting mapred.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
- Setting yarn.nodemanager.remote-app-log-dir=/app-logs
- Setting yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
- Setting mapreduce.map.output.compress=true
- Setting yarn.nodemanager.resource.memory-mb=16384
- Setting yarn.resourcemanager.recovery.enabled=true
- Setting yarn.nodemanager.resource.cpu-vcores=8
Configuring httpfs
Configuring kms
Configuring mapred
- Setting mapreduce.map.java.opts=-Xmx3072m
- Setting mapreduce.reduce.java.opts=-Xmx6144m
- Setting mapreduce.reduce.memory.mb=8192
- Setting yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
- Setting mapreduce.map.memory.mb=4096
- Setting mapred.child.java.opts=-Xmx4096m
- Setting mapreduce.reduce.env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
- Setting mapreduce.framework.name=yarn
- Setting mapreduce.map.env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
Configuring for multihomed network
Exception in thread "main" java.io.FileNotFoundException: hdfs:/schema.movies (No such file or directory)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at java.io.FileInputStream.<init>(FileInputStream.java:93)
at GGCD_Alinea1.ToParquet.getSchema(ToParquet.java:33)
at GGCD_Alinea1.ToParquet.main(ToParquet.java:214)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Disconnected from container.正如您所看到的,它说它找不到schema.movies文件,但是您可以看到它在HDFS中已经存储。是因为它没有使用来自org.apache.hadoop.fs.Path?的路径类。因为当我使用下面的代码(使用readAllBytes()路径)运行一个程序时,它会找到我的数据文件,但是在getSchema()中,我需要使用方法,这就是为什么我不在那里使用Path的原因。
public static void main(String[] args) throws Exception{
long startTime = System.nanoTime();
Job job1 = Job.getInstance(new Configuration(), "ToParquetAlinea1");
job1.setJarByClass(ToParquet.class);
//input
job1.setInputFormatClass(TextInputFormat.class);
MultipleInputs.addInputPath(job1,new Path("hdfs:///title.basics.tsv.gz"),
TextInputFormat.class, ToParquetMapperLeft.class);
MultipleInputs.addInputPath(job1,new Path("hdfs:///title.ratings.tsv.gz"),
TextInputFormat.class, ToParquetMapperRight.class);
job1.setReducerClass(JoinReducer.class);
//output
job1.setOutputKeyClass(Void.class);
job1.setOutputValueClass(GenericRecord.class);
job1.setOutputFormatClass(AvroParquetOutputFormat.class);
AvroParquetOutputFormat.setSchema(job1, getSchema());
FileOutputFormat.setOutputPath(job1,new Path("hdfs:///resultado_parquet"));
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(Text.class);
job1.waitForCompletion(true);
long endTime = System.nanoTime();
long duration = (endTime - startTime)/1000000; //miliseconds
System.out.println("\n\nTIME: " + duration +"\n");
}为什么会这样呢?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-04-05 13:37:12
工作的getSchema()方法是:
public static Schema getSchema() throws IOException {
FileSystem fs = FileSystem.get(new Configuration());
FSDataInputStream s = fs.open(new Path("hdfs:///schema.movies"));
byte[] buf = new byte[10000];
s.read(buf);
String ps = new String(buf);
MessageType mt = MessageTypeParser.parseMessageType(ps);
return new AvroSchemaConverter().convert(mt);
}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66943071
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号