
R中幂律分布的随机数
R中幂律分布的随机数
提问于 2021-03-26 21:23:57
我使用R软件包"poweRlaw“估计并随后从离散幂律分布中提取,但是从拟合中得出的分布似乎与数据不匹配。为了说明这个例子,请参考这个包的指南:https://cran.r-project.org/web/packages/poweRlaw/vignettes/b_powerlaw_examples.pdf。这里,我们首先从包中下载一个示例数据集,然后拟合一个离散幂律。
library("poweRlaw")
data("moby", package = "poweRlaw")
m_pl = displ$new(moby)
est = estimate_xmin(m_pl)
m_pl$setXmin(est)fit看起来不错,因为我们不能放弃这样的假设,即这些数据来自于功率分布(p值> 0.05):
bs = bootstrap_p(m_pl, threads = 8)
bs$p但是,当我们使用内置函数dist_rand()从这个发行版中提取时,生成的发行版将转移到原始发行版的右侧:
set.seed(1)
randNum = dist_rand(m_pl, n = length(moby))
plot(density(moby), xlim = c(0, 1000), ylim = c(0, 1), xlab = "", ylab = "", main = "")
par(new=TRUE)
plot(density(randNum), xlim = c(0, 1000), ylim = c(0, 1), col = "red", xlab = "x", ylab = "Density", main = "")
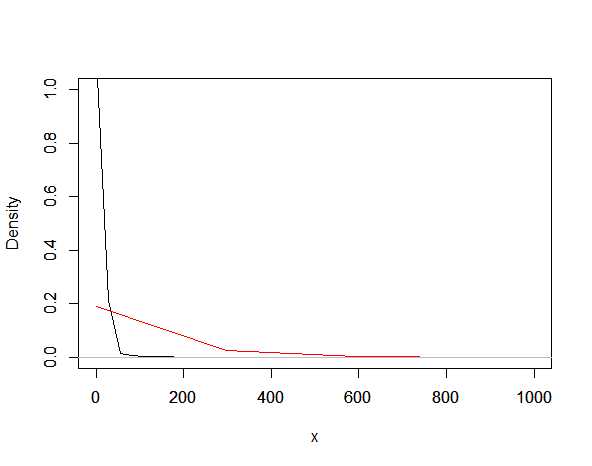
我可能误解了从功率分配中提取的含义,但这是否是因为我们只适合实验分布的尾部(所以我们在参数Xmin之后绘制)?如果这样的事情发生了,我有什么办法来补偿这个事实,使拟合的分布类似于实验分布?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-04-05 15:58:09
所以这里发生了一些事情。
正如您在问题中所暗示的,如果您想比较发行版,需要截断moby,所以moby = moby[moby >= m_pl$getXmin()]
使用
- 使用
density()有点麻烦。这是一个核密度平滑器,它在离散点上绘制正态分布。由于“权力法”有一条很长的尾巴,这是可疑的
。
- 比较两个powerlaw发行版的尾部比较困难(模拟一些数据,请参阅)。
总之,如果你跑
set.seed(1)
x = dist_rand(m_pl, n = length(moby))
# Cut off the tail for visualisation
moby = moby[moby >= m_pl$getXmin() & moby < 100]
plot(density(moby), log = "xy")
x = x[ x < 100]
lines(density(x), col = 2)给出了相当相似的东西。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66824478
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号