
我如何找到最佳的生存分析分类?
我有个关于生存分析的问题。然而,我有以下数据(只是一段摘录):
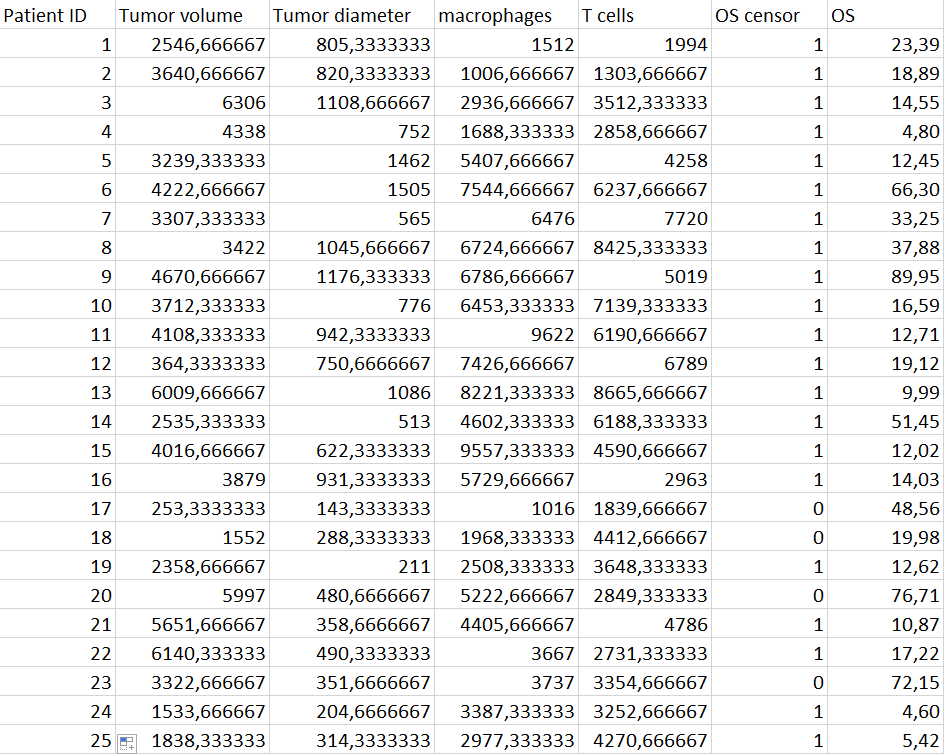
现在,我尝试使用Python生命线包进行生存分析。例如,我想知道T细胞是否影响整体生存(OS).但据我所知,我需要把T细胞的数目分为不同的类别,例如高T细胞和低T细胞.是那么回事吗?但我该怎么找出最合适的人选呢?我的计划是证明高T细胞的肿瘤比低T细胞有更好的存活。但是,我如何才能找到最好的截断值来区分高T细胞和低T细胞,从我这里得到的数据。
有人有主意吗?我的一个朋友说了一些关于“中华民国”的-Analysis,但我现在真的很困惑.如果有什么帮助我会很高兴的!
回答 2
Stack Overflow用户
发布于 2021-05-19 12:44:42
连续变量向范畴变量的转换并不明显。第一种方法可以基于现有的文献,特别是在医学/生物学方面。对现有文献的回顾可能足以创建这些类。另一种方法可以基于T细胞变量的经验分布,有时强调“明显”的分类。使用ROC曲线可能是一个好主意,但不知何故,我认为这是不必要的。在Kaplan型生存分析中对变量进行分类是必要的,但是如果使用Cox模型,则不需要对该变量进行分类。所以我建议你用考克斯回归来做你的生存分析。Cox回归将允许您在建模和交互条件中添加多个预测器,这更方便。
Stack Overflow用户
发布于 2022-08-13 08:32:05
正如gdrouard所建议的,分类可能不是您的最佳选择。在分析连续变量时,使用合适的时间对事件回归模型(如Cox比例风险模型)通常更好。这样做的原因是,如果你人为地对信息进行分类,你基本上就是在丢弃信息。在某些情况下,这也可能导致偏见。
如果您想要可视化连续协变量对事后时间对事件结果的影响,您可能会对我创建的contsurvplot R-包(https://github.com/RobinDenz1/contsurvplot)感兴趣。您可以简单地将您的回归模型插入到其中一个包含的绘图函数中,并得到一个很好的效果图。更多信息可以在关联的预印:https://arxiv.org/pdf/2208.04644.pdf中找到。
https://stackoverflow.com/questions/66813335
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号