
Mellanox ConnectX-5和DPDK在in模式下的奇特行为
最近,我在MellanoxConnectX-5100Gbps网卡上观察到了一种奇特的行为.在100 Gbps的on上工作时,只使用DPDK on模式。据观察,我可以使用12个队列接收142个Mpps。然而,有11个队列,只有96个Mpps,10个Mpps,94个Mpps,9个Mpps。有人能解释为什么捕获性能从11个队列突然跳升到12个队列吗?
下面将介绍设置的详细信息。
我已经把两个服务器连在一起了。其中一个(服务器-1)用于业务生成,另一个(服务器-2)用于业务接收。在这两个服务器中,我都使用MellanoxConnectX-5NIC。report.pdf pg编号:11,12的第3节中提到的性能调优参数已被遵循。
这两台服务器的配置是相同的。
服务器配置
- 处理器: Intel Xeon可伸缩处理器,6148系列,20核HT,2.4 GHz,27.5 L3缓存
- 不是的。处理器的编号:4
- RAM: 256 GB,2666 MHz速度
DPDK版本为dpdk-19.11,操作系统为RHEL-8.0
对于流量生成,使用--forward=txonly和-txonly-多流进行测试and。使用的命令如下。
服务器-1中的数据包生成testpmd命令
/testpmd -l 4,5,6,7,9,10,12,13,14,15,16 -n 6 -w 17:00.0,mprq_en=1,rxq_pkt_pad_en=1 -socket-mem=4096,0,0-0 --socket-num=0 -- num=0-txd=64-txd=4096-rxd=4096-mbcache=512-rxq=12-txq=12-txq nb-=12 -i -a -rss-ip-no前进=txq纯-txq多流
testpmd> set txpkts 64它能够以142.2 Mpps的持续速率生成64个字节分组。这被用作第二台服务器的输入,第二台服务器在in模式下工作。接收命令如下所述
在服务器-2中有12个核心的数据包接收命令
/testpmd -l 4,5,6,7,9,10,12,13,14,15,16 -n 6 -w 17:00.0,mprq_en=1,rxq_pkt_pad_en=1 -socket-mem=4096,0,0-0 --socket-num=0 -num=64-txd=4096-rxd=4096-mbcache=512-rxq=12-txq=12-nb核=12 -i -a -rss-ip-no-numa
testpmd> set fwd rxonly
testpmd> show port stats all
######################## NIC statistics for port 0 ########################
RX-packets: 1363328297 RX-missed: 0 RX-bytes: 87253027549
RX-errors: 0
RX-nombuf: 0
TX-packets: 19 TX-errors: 0 TX-bytes: 3493
Throughput (since last show)
Rx-pps: 142235725 Rx-bps: 20719963768
Tx-pps: 0 Tx-bps: 0
############################################################################在服务器-2中具有11个核心的数据包接收命令
/testpmd -l 4,5,6,8,9,10,12,13,14,15 -n 6 -w 17:00.0,mprq_en=1,rxq_pkt_pad_en=1 -socket-mem=4096,0,0-0 --socket-num=0 -txd=64-txd=4096-rxd=4096-rxd=512-rxq=11-txq=11-nb核=11 -i -a -rss-ip-no-numa
testpmd> set fwd rxonly
testpmd> show port stats all
######################## NIC statistics for port 0 ########################
RX-packets: 1507398174 RX-missed: 112937160 RX-bytes: 96473484013
RX-errors: 0
RX-nombuf: 0
TX-packets: 867061720 TX-errors: 0 TX-bytes: 55491950935
Throughput (since last show)
Rx-pps: 96718960 Rx-bps: 49520107600
Tx-pps: 0 Tx-bps: 0
############################################################################如果你看到Rx从11个核心突然跃升到12个核心。在其他地方没有观察到这种变化,如8至9、9至10或10至11等等。
有谁能解释一下为什么突然跳起来的原因。
同样的实验也被进行了,这次使用了11个核心来产生流量。
/testpmd -l 4,5,6,8,9,10,12,13,14,15 -n 6 -w 17:00.0,mprq_en=1,rxq_pkt_pad_en=1 -socket-mem=4096,0,0-0 --socket-num=0 -num=0-txd=4096-rxd=4096-rxd=512-rxq=11-txq=11-rxq=11 -i -a -rss-ip-no-numa-前进=txonly核-txd-纯多流
testpmd> show port stats all
######################## NIC statistics for port 0 ########################
RX-packets: 0 RX-missed: 0 RX-bytes: 0
RX-errors: 0
RX-nombuf: 0
TX-packets: 2473087484 TX-errors: 0 TX-bytes: 158277600384
Throughput (since last show)
Rx-pps: 0 Rx-bps: 0
Tx-pps: 142227777 Tx-bps: 72820621904
############################################################################在捕获端有11个核
/testpmd -l 1,2,3,5,6,11,12,13,14,15 -n 6 -w 17:00.0,mprq_en=1,rxq_pkt_pad_en=1 -socket-mem=4096,0,0-0 --socket-num=0 -num=0-txd=1024-rxd=1024-rxd=512-rxq=512-rxq=11-txq=11 -i -a -rss-ip-no-numa
testpmd> set fwd rxonly
testpmd> show port stats all
######################## NIC statistics for port 0 ########################
RX-packets: 8411445440 RX-missed: 9685 RX-bytes: 538332508206
RX-errors: 0
RX-nombuf: 0
TX-packets: 0 TX-errors: 0 TX-bytes: 0
Throughput (since last show)
Rx-pps: 97597509 Rx-bps: 234643872
Tx-pps: 0 Tx-bps: 0
############################################################################在捕获端有12个核心
/testpmd -l 1,2,3,5,6,10,12,13,14,15,16 -n 6 -w 17:00.0,mprq_en=1,rxq_pkt_pad_en=1 -socket-mem=4096,0,0,0 --socket-num=0 -num=64-txd=1024-rxd=1024-mbcache=512-rxq=12-txq=12-nb核=12 -i -a -rss-ip-no-numa
testpmd> set fwd rxonly
testpmd> show port stats all
######################## NIC statistics for port 0 ########################
RX-packets: 9370629638 RX-missed: 6124 RX-bytes: 554429504128
RX-errors: 0
RX-nombuf: 0
TX-packets: 0 TX-errors: 0 TX-bytes: 0
Throughput (since last show)
Rx-pps: 140664658 Rx-bps: 123982640
Tx-pps: 0 Tx-bps: 0
############################################################################性能从11到12的突然跃升仍然保持不变。
回答 1
Stack Overflow用户
发布于 2022-07-13 01:29:42
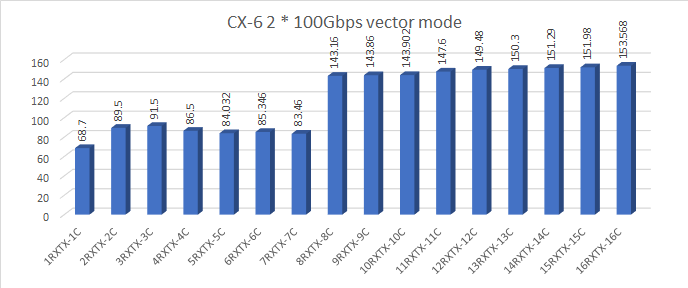
对于19.11、20.11、21.11的DPDK版本,MellanoxCX-5和CX-6仅以向量模式(默认模式)运行,不会产生上述问题。
编辑-1与rxqs_min_mprq=1重新测试2*100 10Mpps为64B,16 RXTX在16T16C上导致9~10 10Mpps的降解。对于从1到7RX的所有RX队列,使用rxqs_min_mprq=1都会减少6Mpp。
以下是RXTX到核心缩放的捕获
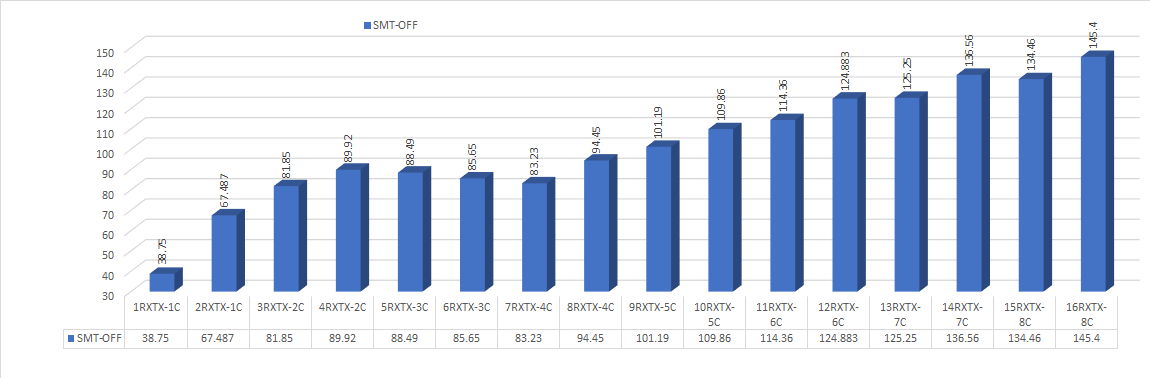
对MPRQ索赔的调查,以下是一些独特的观察结果
- 对于MLX CX-5和CX-6,每个RX队列可以达到的最大值约为36到38 MPPs。
- 使用AMD米兰在CX-5和CX-6上使用AMD米兰,使用3RXTX在IO中可以实现高达90 90Mpps (64B)的单核。
- 对于100 mode,64B可以用14个逻辑核(7个物理核)在IO模式下用testpmd实现。
- 对于CX-5和CX-6-2*100 MPRQ,64B都需要MPRQ和压缩技术来允许更多的数据包进出系统。
- 要实现高数量的配置,需要大量的配置调优。有关更多信息,请参考堆栈过流问题和DPDK MLX调谐参数。
PCIe gen4 BW不是限制因素,但内嵌siwtch的NIC ASIC导致了上述行为。因此,要克服这些限制,需要使用PMD参数来激活硬件,这进一步增加了PMD处理过程中CPU的开销。因此,有障碍(需要更多的cpu)来处理压缩和多个包内联,以转换为DPDK单MBUF。这就是为什么在使用PMD参数时需要更多的therad的原因。
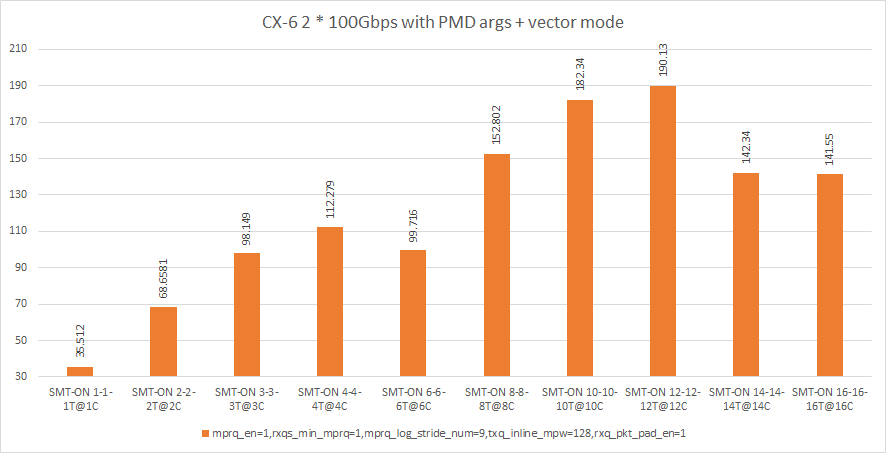
注意:
Test application: testpmd
EAL Args: --in-memory --no-telemetry --no-shconf --single-file-segments --file-prefix=2 -l 7,8-31
PMD args vector: none
PMD args for 2 * 100Gbps line rate: txq_inline_mpw=204,txqs_min_inline=1,mprq_en=1,rxqs_min_mprq=1,mprq_log_stride_num=12,rxq_pkt_pad_en=1,rxq_cqe_comp_en=4https://stackoverflow.com/questions/66711987
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号