
python中泊松分布的拟合
python中泊松分布的拟合
提问于 2021-03-18 08:25:58
我有数据分布,我想要拟合泊松分布。我的数据是这样的:
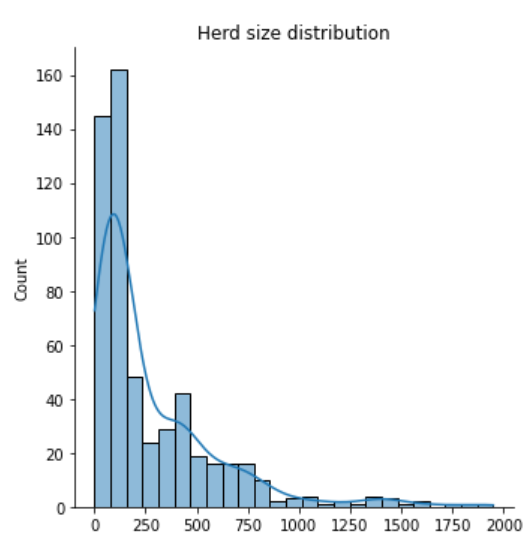
我试着适应:
mu = herd_size["COW_NUM"].mean()
ax=sns.displot(data=herd_size["COW_NUM"], kde=True)
ax.set(xlabel='Size',title='Herd size distribution & poisson distribution')
plt.plot(np.arange(0, 2000, 80), [st.poisson.pmf(np.arange(i, i+80), mu).sum()*len(herd_size["COW_NUM"])
for i in np.arange(0, 2000, 80)], color='red')
#every bin contain approximatly 80 observes
plt.show()但我得到了不一样的东西:
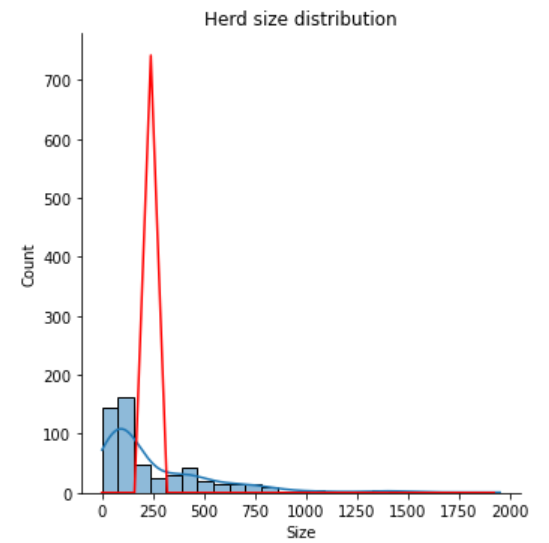
UPDATE I尝试使用以下代码应用负binom发行版:
n=len(herd_size["COW_NUM"])
p =herd_size["COW_NUM"].mean()/(herd_size["COW_NUM"].mean()+2)
ax=sns.displot(data=herd_size["COW_NUM"], kde=True)
ax.set(xlabel='Size',title='Herd size distribution & geometry distribution')
plt.plot(np.arange(0, 2000, 80), [st.nbinom.pmf(np.arange(i, i+80), n,p).sum()*len(herd_size["COW_NUM"])
for i in np.arange(0, 2000, 80)], color='red')
#every bin contain approximatly 80 observes
plt.show()但我得到了这个:nbinom
{kind=link}
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-03-18 14:49:04
您的情节是正确的(至少大约),问题是如何将您的数据建模为Poisson。随着lambda变大,Poisson看起来越来越像正态分布--参见维基百科的这块地。泊松分布的方差等于它的平均值,所以当平均值在240左右时,标准偏差为15.5。最终的结果是泊松(240)的结果应该在210到270之间压倒性的下降,这就是你的红色情节所显示的。尝试将不同的分布安装到您的数据中。
{kind=link}
我刚发现了StupidWolf的答案。除了使用200而不是240的平均值之外,他的直方图还显示了上面描述的相同的行为。
Stack Overflow用户
发布于 2021-03-18 14:15:04
对于您需要绘制的内容,可能更容易提供用来绘制直方图的回收箱:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import poisson
herd_size = pd.DataFrame({'COW_NUM':np.random.poisson(200,2000)})
binwidth = 10
xstart = 150
xend = 280
bins = np.arange(xstart,xend,binwidth)
o = sns.histplot(data=herd_size["COW_NUM"], kde=True,bins = bins)然后计算你的平均数和总数:
mu = herd_size["COW_NUM"].mean()
n = len(herd_size)预期的频率是在您的左和右间隔的开始和结束之间的差异:
plt.plot(bins + binwidth/2 , n*(poisson.cdf(bins+binwidth,mu) - poisson.cdf(bins,mu)), color='red')
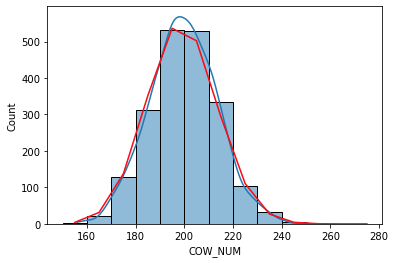
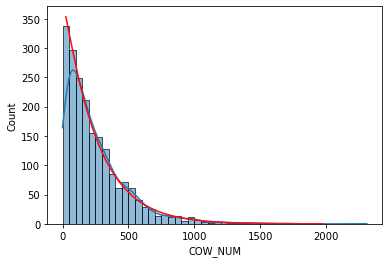
您的数据过于分散,因为对于泊松来说,您并不期望数据会如此分散。因此,您需要做的是使用伽马或负二项式来适应它,例如:
from scipy.stats import nbinom
herd_size = pd.DataFrame({'COW_NUM':nbinom.rvs(n=2,p=0.1,loc=240,size=2000)})
binwidth = 50
xstart = 0
xend = 2000
bins = np.arange(xstart,xend,binwidth)
herd_size = pd.DataFrame({'COW_NUM':nbinom.rvs(n=1,p=0.004,size=2000)})
Var = herd_size["COW_NUM"].var()
mu = herd_size["COW_NUM"].mean()
p = (mu/Var)
r = mu**2 / (Var-mu)
n = len(herd_size)
o = sns.histplot(data=herd_size["COW_NUM"], kde=True,bins=bins)
plt.plot(bins + binwidth/2 ,
n*(nbinom.cdf(bins+binwidth,r,p) - nbinom.cdf(bins,r,p)),
color='red')
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66687274
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号