
从dataframe中提取值并将它们填充到R中的模板短语中
从dataframe中提取值并将它们填充到R中的模板短语中
提问于 2021-02-24 09:58:57
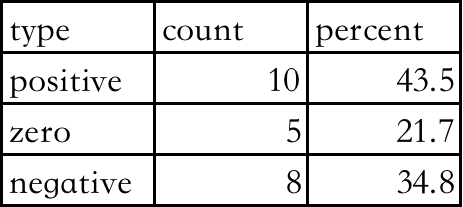
给定数据集如下:
df <- structure(list(type = structure(c(2L, 3L, 1L), .Label = c("negative",
"positive", "zero"), class = "factor"), count = c(10L, 5L, 8L
), percent = c(43.5, 21.7, 34.8)), class = "data.frame", row.names = c(NA,
-3L))退出:
我希望将表中的值填充到模板短语中,如下所示:
2020年,10城市有positive增长,占所有城市的43.5 %;5城市有zero增长,占所有城市的21.7 %;8城市有negative增长,占所有城市的21.7 %。
模板:
在2020年,{}城市有{}增长,占所有城市的{} %;{}城市具有{}E 220增长,其中包括所有城市中E 121{}{}{222%;e 123{}e 224城市有E 125{}<代码>E 226增长,其中包括E 127{{E 228%。
我怎么能在R里这么做?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-02-24 10:07:55
您可以使用paste0/sprintf创建一个简单的句子,并从dataframe中更改具有各自值的占位符。
这是另一种不需要从dataframe列出每个单独值的方法。
string <- 'In 2020, we have %s cities have %s growth, which covers %s %% of all cities; %s cities have %s growth, which covers %s %% of all cities; and %s cities have %s growth, which covers %s %% of all cities'
do.call(sprintf, c(as.list(c(t(df[c(2, 1, 3)]))), fmt = string))
#[1] "In 2020, we have 10 cities have positive growth, which covers 43.5 % of all #cities; 5 cities have zero growth, which covers 21.7 % of all cities; and 8 #cities have negative growth, which covers 34.8 % of all cities"df[c(2, 1, 3)]用于重新排序列,以便count为第一列,type为第二列。这是必要的,因为您的句子总是首先具有count值,然后是type和最后一个percent。c(t(df[c(2, 1, 3)]))以逐行方式将dataframe更改为向量,这将作为不同的参数传递给sprintf。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66348541
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号