
NSIGHT计算: SOL SM对Roofline
我在我的cuda内核上运行了Cud-11.2 nsight-计算。
它报告说,SOL SM是79.44%,我的解释是非常接近最大值。SOL L1为48.38%
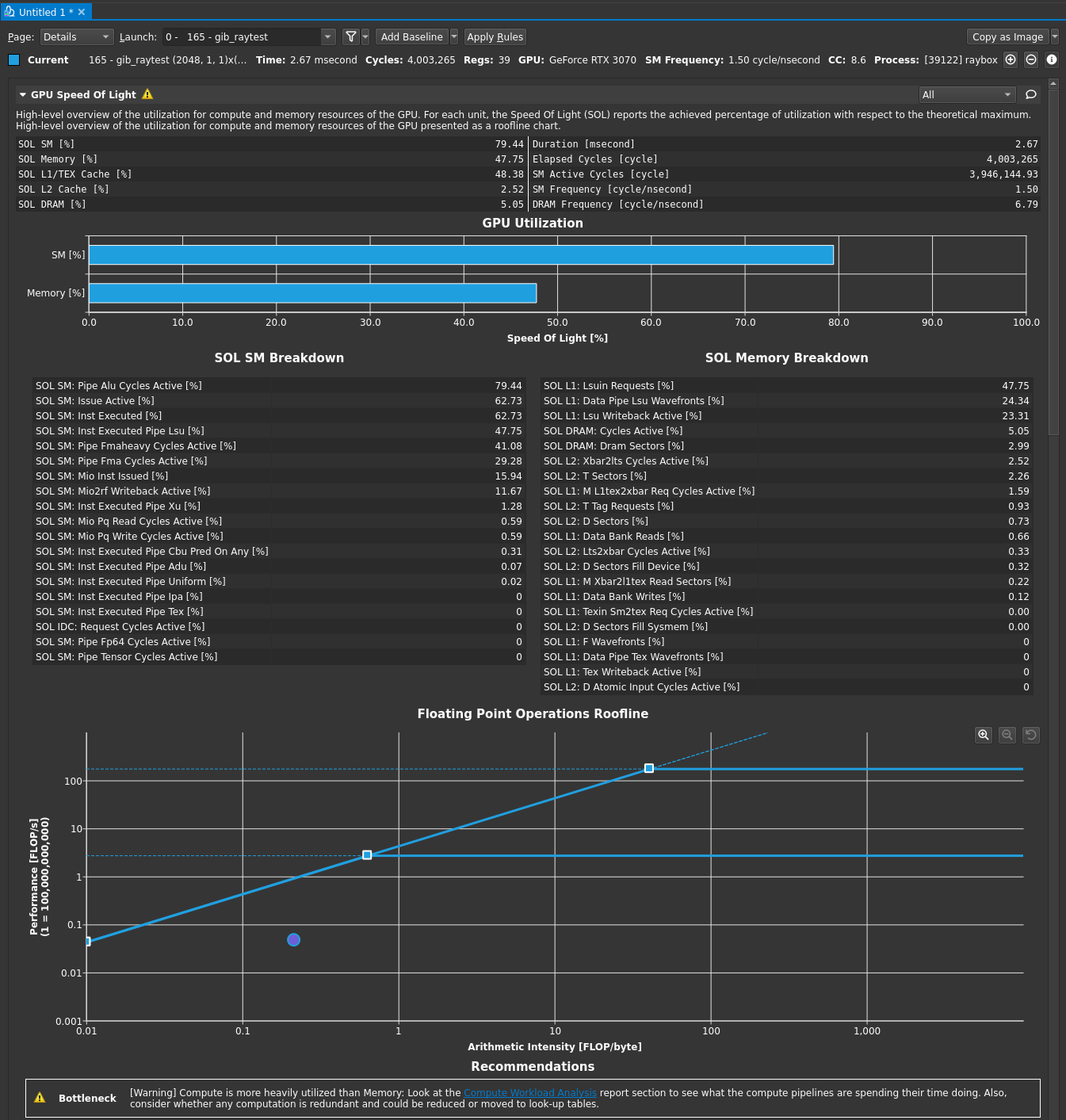
当我检查车顶图表时,我发现我的测量结果离峰值性能很远。
实现了:4.7GFLOP/s。
峰位于:93 GFlop/s左右。
我还在80+%上看到了ALU管道的使用情况
那么,如果ALU管得到了充分的利用,那么根据roofline图,为什么达到的性能要低得多呢?
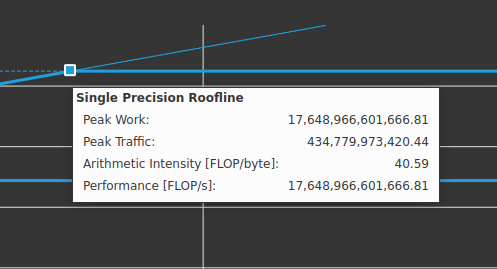
请注意,这是在RTX 3070上进行的,它的单精度峰值为17.6TFLOP/s:
更新
我想我知道这是怎么回事.@使我走上了正确的轨道,表明ALU是整数运算,因此不包括在内。而且这些并不是唯一不包括在内的操作!
Roofline图只显示fp32和fp64操作,而不显示fp16操作.
我的代码工作在半精度浮动,使Roofline图表不适用于我的代码,我怀疑。
回答 1
Stack Overflow用户
发布于 2021-01-09 05:15:35
那么,如果ALU管得到了充分的利用,那么根据roofline图,为什么达到的性能要低得多呢?
因为ALU管道、与浮点无关和roofline图本质上只是关于浮点的。
如我所链接的答案所示,ALU管道处理:
大多数整数指令、位操作指令和逻辑指令
这种管道利用率很有可能是限制内核性能的一个因素,因此,您的运行速度/s速率/吞吐量低于其他情况下可以实现的浮点级(即roofline)。
( fp32 32/fp32 64)浮点相关的项目有fma、fmaheavy、fp32和潜在的张量。这些都是在大约40%或以下的活动,所以你没有最大的那些管道。
https://stackoverflow.com/questions/65633300
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号