
根据SQL Server中每个客户的事务日期时间序列计算的累计净流出流
我试图按照事务发生顺序(DateTime ASC)为每个客户获取净流出流。为此,我创建了一个循环查询,但不幸的是,它需要大量时间来处理。20K记录花了8分钟,而我要在500万条记录上运行它。
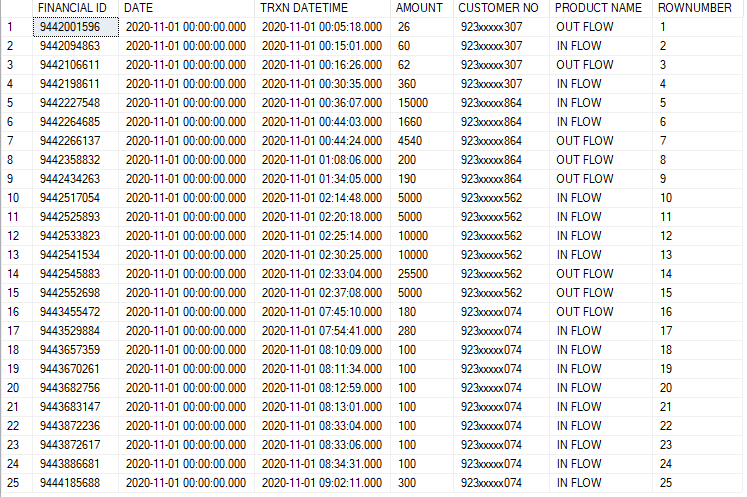
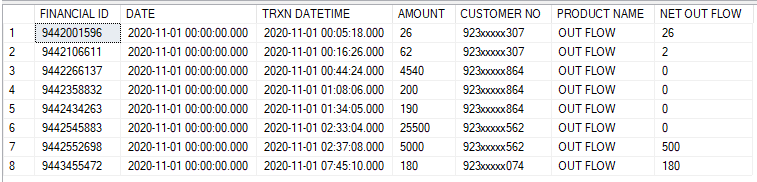
说明:例如,客户923xxxx307已经完成了4项事务,下面是如何工作的说明。
- 在样例数据表中,第一次交易是出流,他在这里使用了26卢比,这就是为什么在要求的输出表中,第一行的净流出流是样本数据表中的26
- ,第二次交易是在流中,他将60卢比存入他的帐户,这60卢比应该停在他自己单独的桶里,这不应该反映在样本数据表中所要求的表
- 中,第三,事务是出流,他在帐户中使用了62卢比,脚本应该减去在第2点中维护的桶中的62卢比,因此在所需的输出表中,净流出流列应该显示2,即(62-60 = 2)。此外,他的桶应该变成0,因为它是在示例数据表中的第三事务
- 中完全消耗的,而第四事务又是在流中,他将360卢比存入他的帐户,所以他的桶应该再次显示360卢比,不影响所需的输出表。等等。
此桶将用于next OUT FLOW事务,或者如果下一个事务再次处于流中,则应将新事务的数量添加到桶中现有的360中。
我还为您的测试运行添加了带有小样本数据集的完整SQL脚本。
请帮我找到一些有效的解决方案。我附上了输入和输出屏幕截图以及我的代码。
-- Creating SAMPLE DATA Table ---
DROP TABLE IF EXISTS #TestData
CREATE TABLE #TestData
(
[FINANCIAL ID] BIGINT,
[DATE] DATETIME,
[TRXN DATETIME] DATETIME,
AMOUNT FLOAT,
[CUSTOMER NO] VARCHAR(20),
[PRODUCT NAME] VARCHAR(10)
)
GO
-- Inserting Sample Date in above table ---
INSERT INTO #TestData
VALUES (9442001596,'2020-11-01','2020-11-01 00:05:18',26,'923xxxxx307','OUT FLOW')
INSERT INTO #TestData
VALUES (9442094863,'2020-11-01','2020-11-01 00:15:01',60,'923xxxxx307','IN FLOW')
INSERT INTO #TestData
VALUES (9442106611,'2020-11-01','2020-11-01 00:16:26',62,'923xxxxx307','OUT FLOW')
INSERT INTO #TestData
VALUES (9442198611,'2020-11-01','2020-11-01 00:30:35',360,'923xxxxx307','IN FLOW')
INSERT INTO #TestData
VALUES (9442227548,'2020-11-01','2020-11-01 00:36:07',15000,'923xxxxx864','IN FLOW')
INSERT INTO #TestData
VALUES (9442264685,'2020-11-01','2020-11-01 00:44:03',1660,'923xxxxx864','IN FLOW')
INSERT INTO #TestData
VALUES (9442266137,'2020-11-01','2020-11-01 00:44:24',4540,'923xxxxx864','OUT FLOW')
INSERT INTO #TestData
VALUES (9442358832,'2020-11-01','2020-11-01 01:08:06',200,'923xxxxx864','OUT FLOW')
INSERT INTO #TestData
VALUES (9442434263,'2020-11-01','2020-11-01 01:34:05',190,'923xxxxx864','OUT FLOW')
INSERT INTO #TestData
VALUES (9442517054,'2020-11-01','2020-11-01 02:14:48',5000,'923xxxxx562','IN FLOW')
INSERT INTO #TestData
VALUES (9442525893,'2020-11-01','2020-11-01 02:20:18',5000,'923xxxxx562','IN FLOW')
INSERT INTO #TestData
VALUES (9442533823,'2020-11-01','2020-11-01 02:25:14',10000,'923xxxxx562','IN FLOW')
INSERT INTO #TestData
VALUES (9442541534,'2020-11-01','2020-11-01 02:30:25',10000,'923xxxxx562','IN FLOW')
INSERT INTO #TestData
VALUES (9442545883,'2020-11-01','2020-11-01 02:33:04',25500,'923xxxxx562','OUT FLOW')
INSERT INTO #TestData
VALUES (9442552698,'2020-11-01','2020-11-01 02:37:08',5000,'923xxxxx562','OUT FLOW')
INSERT INTO #TestData
VALUES (9443455472,'2020-11-01','2020-11-01 07:45:10',180,'923xxxxx074','OUT FLOW')
INSERT INTO #TestData
VALUES (9443529884,'2020-11-01','2020-11-01 07:54:41',280,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443657359,'2020-11-01','2020-11-01 08:10:09',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443670261,'2020-11-01','2020-11-01 08:11:34',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443682756,'2020-11-01','2020-11-01 08:12:59',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443683147,'2020-11-01','2020-11-01 08:13:01',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443872236,'2020-11-01','2020-11-01 08:33:04',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443872617,'2020-11-01','2020-11-01 08:33:06',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9443886681,'2020-11-01','2020-11-01 08:34:31',100,'923xxxxx074','IN FLOW')
INSERT INTO #TestData
VALUES (9444185688,'2020-11-01','2020-11-01 09:02:11',300,'923xxxxx074','IN FLOW')
-- Ranked table with ROW NUMBERS ---
DROP TABLE IF EXISTS #TestData_Ranked
SELECT *, ROWNUMBER = ROW_NUMBER() OVER (ORDER BY td.[FINANCIAL ID])
INTO #TestData_Ranked
FROM #TestData td
GO
CREATE UNIQUE CLUSTERED INDEX [CI_ROWNUMBER] ON #TestData_Ranked (ROWNUMBER ASC)
GO
-- Main Query to get OUTPUT DATA table ---
DECLARE @start BIGINT = (SELECT MIN(iios.ROWNUMBER) FROM #TestData_Ranked iios)
DECLARE @end BIGINT = (SELECT MAX(iios.ROWNUMBER) FROM #TestData_Ranked iios)
DROP TABLE IF EXISTS #ibft_in
CREATE TABLE #ibft_in ([CUSTOMER NO] VARCHAR(20), [TRXN DATETIME] DATETIME, AMOUNT FLOAT)
DROP TABLE IF EXISTS #ibft_out
SELECT TOP(0) iios.[FINANCIAL ID], iios.DATE, iios.[TRXN DATETIME], iios.AMOUNT, iios.[CUSTOMER NO], iios.[PRODUCT NAME], 0 AS [NET OUT FLOW]
INTO #ibft_out
FROM #TestData_Ranked iios
WHILE (@start <= @end)
BEGIN
DECLARE @cur_FinancialId BIGINT = (SELECT [FINANCIAL ID] FROM #TestData_Ranked WHERE ROWNUMBER = @start)
DECLARE @cur_TrxnDateTime DATETIME = (SELECT [TRXN DATETIME] FROM #TestData_Ranked WHERE ROWNUMBER = @start)
DECLARE @cur_Date DATE = (SELECT DATE FROM #TestData_Ranked WHERE ROWNUMBER = @start)
DECLARE @cur_Amount FLOAT = (SELECT AMOUNT FROM #TestData_Ranked WHERE ROWNUMBER = @start)
DECLARE @cur_Customer_No VARCHAR(20) = (SELECT [CUSTOMER NO] FROM #TestData_Ranked WHERE ROWNUMBER = @start)
DECLARE @cur_ProductName VARCHAR(10) = (SELECT [PRODUCT NAME] FROM #TestData_Ranked WHERE ROWNUMBER = @start)
DECLARE @IN_IfExists INT = (SELECT COUNT(*) FROM #ibft_in ii WHERE ii.[CUSTOMER NO] = @cur_Customer_No)
DECLARE @IN_Amount FLOAT = ISNULL((SELECT ISNULL(ii.AMOUNT, 0) FROM #ibft_in ii WHERE ii.[CUSTOMER NO] = @cur_Customer_No), 0)
DECLARE @Remaining_Amount FLOAT = ISNULL(CASE WHEN (@cur_Amount - @IN_Amount)<0 THEN 0 ELSE (@cur_Amount - @IN_Amount) END, 0)
PRINT @start
PRINT @cur_Amount
PRINT @IN_Amount
IF (@cur_ProductName = 'IN FLOW' AND @IN_IfExists = 0)
BEGIN
INSERT INTO #ibft_in
VALUES (@cur_Customer_No, @cur_TrxnDateTime, @cur_Amount)
END
ELSE
BEGIN
IF (@cur_ProductName = 'IN FLOW' AND @IN_IfExists > 0)
BEGIN
UPDATE #ibft_in
SET
[TRXN DATETIME] = @cur_TrxnDateTime,
AMOUNT = @IN_Amount + @cur_Amount
WHERE
[CUSTOMER NO] = @cur_Customer_No
END
ELSE
BEGIN
IF (@cur_ProductName = 'OUT FLOW')
BEGIN
INSERT INTO #ibft_out
VALUES (@cur_FinancialId, @cur_Date, @cur_TrxnDateTime, @cur_Amount, @cur_Customer_No, @cur_ProductName, @Remaining_Amount)
UPDATE #ibft_in
SET
AMOUNT = CASE WHEN (@IN_Amount - @cur_Amount)<0 THEN 0 ELSE (@IN_Amount - @cur_Amount) END
WHERE
[CUSTOMER NO] = @cur_Customer_No
END
END
END
SET @start = @start + 1
END
--------------------------------------------样本数据
所需输出
回答 1
Stack Overflow用户
发布于 2020-12-01 01:31:10
编辑
从技术上讲,这仍然是一个RBAR查询,刚刚重写。我没有足够的样本数据来知道性能是什么样的,所以很明显,请根据20k数据集来比较速度,但是这使用CTE而不是游标。注意,这直接从您的-- Ranked table with ROW NUMBERS ---行开始:
-- Ranked table with ROW NUMBERS ---
DROP TABLE IF EXISTS #TestData_Ranked
SELECT *,
--ROWNUMBER = ROW_NUMBER() OVER (ORDER BY td.[FINANCIAL ID]),
TrxTypeSEQ = ROW_NUMBER() over (PARTITION BY [customer no] ORDER BY [trxn datetime])
INTO #TestData_Ranked
FROM #TestData td
GO
-- not unique but still an index
CREATE CLUSTERED INDEX [CI_ROWNUMBER] ON #TestData_Ranked (TrxTypeSEQ ASC)
GO
DROP TABLE IF EXISTS #ibft_out;
WiTH SortedTrx AS (
SELECT
[Financial ID],
[Date],
[Trxn Datetime],
[Amount],
[Customer No],
[Product Name],
TrxTypeSEQ,
BUCKET = case when [Product Name] = 'IN FLOW' then Amount ELSE 0 END,
NETOUT = case when [Product Name] = 'OUT FLOW' then Amount ELSE 0 END
FROM #TestData_Ranked
WHERE TrxTypeSEQ = 1
UNION ALL
SELECT
AllTrx.[Financial ID],
AllTrx.[Date],
AllTrx.[Trxn Datetime],
AllTrx.[Amount],
AllTrx.[Customer No],
AllTrx.[Product Name],
AllTrx.TrxTypeSEQ,
BUCKET = case when AllTrx.[Product Name] = 'IN FLOW' then SortedTrx.Bucket + AllTrx.Amount
ELSE
case when AllTrx.[Amount] > SortedTrx.Bucket then 0 else SortedTrx.Bucket - AllTrx.[Amount] end
END,
NETOUT = case when AllTrx.[Product Name] = 'IN FLOW' then 0
else
case when AllTrx.[Amount] < SortedTrx.Bucket then 0 else AllTrx.[Amount] - SortedTrx.Bucket end
END
FROM #TestData_Ranked AllTrx
INNER JOIN SortedTrx ON AllTrx.[customer no] = SortedTrx.[customer no] AND SortedTrx.TrxTypeSEQ + 1 = AllTrx.TrxTypeSEQ
)
SELECT
[Financial ID],
[Date],
[Trxn Datetime],
[Amount],
[Customer No],
[Product Name],
NETOUT
INTO #ibft_out
FROM SortedTrx
WHERE [Product Name] = 'OUT FLOW'
ORDER BY [Trxn Datetime]
SELECT * FROM #ibft_out原始
要将WHILE循环重写为CURSOR,将将查询#TestData_Ranked的次数从6次减少到1次;而不是每次查询#ibft_in 3x,而是根据事务类型,只查询一次或两次。我很想知道它提供了什么样的性能;使用您的代码,样例数据运行在7s中,执行计划分析和40多岁以上的数据运行在一起。
将-- Main Query to get OUTPUT DATA table ---行之后的所有内容替换为:
-- Create our useful tables for IN & OUT calculations
DROP TABLE IF EXISTS #ibft_in
CREATE TABLE #ibft_in ([CUSTOMER NO] VARCHAR(20), [TRXN DATETIME] DATETIME, AMOUNT FLOAT)
DROP TABLE IF EXISTS #ibft_out
SELECT TOP(0) iios.[FINANCIAL ID], iios.DATE, iios.[TRXN DATETIME], iios.AMOUNT, iios.[CUSTOMER NO], iios.[PRODUCT NAME], 0 AS [NET OUT FLOW]
INTO #ibft_out
FROM #TestData_Ranked iios
-- Declare these once, outside a loop, to cut down on wasted work
DECLARE @currRow INT = 0,
@currFinancialID BIGINT = 0,
@currDateTime DATETIME,
@currAmt FLOAT,
@currCustomer VARCHAR(20),
@currTrxType VARCHAR(10),
@fundsAvailable FLOAT;
-- We want a one-way cursor as fast as we can
DECLARE trx_cursor CURSOR LOCAL FAST_FORWARD FOR
SELECT
ROWNUMBER,
[Financial ID],
[Trxn Datetime],
[Amount],
[Customer No],
[Product Name]
FROM #TestData_Ranked
ORDER BY ROWNUMBER ASC
OPEN trx_cursor
FETCH NEXT FROM trx_cursor INTO @currRow,
@currFinancialID,
@currDateTime,
@currAmt,
@currCustomer,
@currTrxType
WHILE @@FETCH_STATUS = 0
BEGIN
-- If this is an IN transaction, INSERT or UPDATE our bucket of rupees
IF @currTrxType = 'IN FLOW'
MERGE #ibft_in as Tgt
USING (select @currCustomer as cno, @currDateTime as dt, @currAmt as amt) as Src
ON tgt.[CUSTOMER NO] = cno
WHEN NOT MATCHED BY TARGET THEN INSERT
VALUES (cno, dt, amt)
WHEN MATCHED THEN UPDATE
SET Tgt.[TRXN DATETIME] = dt,
Tgt.AMOUNT = tgt.amount + amt;
-- OTHERWISE, calculate our NET OUT
ELSE
BEGIN
SELECT @fundsAvailable = ISNULL((SELECT ISNULL(ii.AMOUNT, 0) FROM #ibft_in ii WHERE ii.[CUSTOMER NO] = @currCustomer), 0)
INSERT INTO #ibft_out
VALUES (
@currFinancialID,
CAST(@currDateTime as DATE),
@currDateTime,
@currAmt,
@currCustomer,
@currTrxType,
ISNULL(CASE WHEN (@currAmt - @fundsAvailable)<0 THEN 0 ELSE (@currAmt - @fundsAvailable) END, 0)
)
UPDATE #ibft_in
SET AMOUNT = CASE WHEN (@fundsAvailable - @currAmt)<0 THEN 0 ELSE (@fundsAvailable - @currAmt) END
WHERE [CUSTOMER NO] = @currCustomer
END
FETCH NEXT FROM trx_cursor INTO @currRow,
@currFinancialID,
@currDateTime,
@currAmt,
@currCustomer,
@currTrxType
END
CLOSE trx_cursor
DEALLOCATE trx_cursor
select * from #ibft_in
select * from #ibft_outhttps://stackoverflow.com/questions/65070514
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号