
基于一列的标准化r函数?
基于一列的标准化r函数?
提问于 2020-11-17 10:18:45
是否有可能根据最后一列(样本)样本=测序基因组的数量,在R中规范此表。所以我想得到所有基因在所有条件下的正常分布。
简化了我的数据示例:
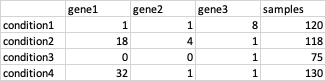
我试过:
dat1 <- read.table(text = " gene1 gene2 gene3 samples
condition1 1 1 8 120
condition2 18 4 1 118
condition3 0 0 1 75
condition4 32 1 1 130", header = TRUE)
dat1<-normalize(dat1, method = "standardize", range = c(0, 1), margin = 1L, on.constant = "quiet")但结果包括负值,我不知道这种方法有多有用。有谁能建议我如何规范我的数据..。才能得到有意义的结果。
谢谢,如果这是个愚蠢的问题,我很抱歉。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-11-17 15:10:38
使用您的数据,首先编写一个min max函数:
minmax = function(x){ (x-min(x))/(max(x)-min(x))}然后遍历这些列:
norm = data.frame(lapply(dat1[,1:3],function(i) minmax(i/dat1$samples)))看起来是这样的,我希望这是正确的
gene1 gene2 gene3
1 0.03385417 0.2458333 1.00000000
2 0.61970339 1.0000000 0.01326455
3 0.00000000 0.0000000 0.09565217
4 1.00000000 0.2269231 0.00000000页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64873299
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号