
R car的更快替代::Anova用于平方交叉积矩阵的计算,用于预测子集
我需要用Y (n )和X (n )来计算多元线性模型中的平方交叉积矩阵之和(实际上是这个矩阵的迹)。这样做的标准R代码是:
require(MASS)
require(car)
# Example data
q <- 10
n <- 1000
p <- 10
Y <- mvrnorm(n, mu = rep(0, q), Sigma = diag(q))
X <- as.data.frame(mvrnorm(n, mu = rnorm(p), Sigma = diag(p)))
# Fit lm
fit <- lm( Y ~ ., data = X )
# Type I sums of squares
summary(manova(fit))$SS
# Type III sums of squares
type = 3 # could be also 2 (II)
car::Anova(fit, type = type)$SSP这需要做数千次,不幸的是,当预测器的数量相对较大时,速度会变慢。由于我通常只对s预测器的一个子集感兴趣,所以我尝试重新实现这个计算。虽然我的实现直接转换线性代数的s =1(下面)是更快的小样本大小(n),
# Hat matrix (X here stands for the actual design matrix)
H <- tcrossprod(tcrossprod(X, solve(crossprod(X))), X)
# Remove predictor of interest (e.g. 2)
X.r <- X[, -2]
H1 <- tcrossprod(tcrossprod(X.r, solve(crossprod(X.r))), X.r)
# Compute e.g. type III sum of squares
SS <- crossprod(Y, H - H1) %*% Y对于大型n,car仍然运行得更快:
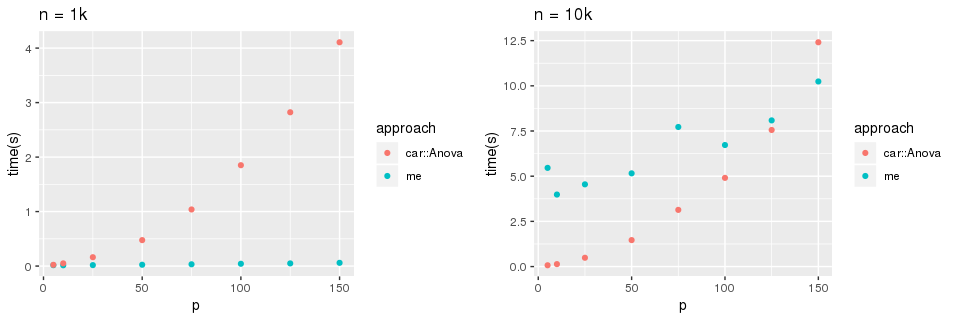
我已经尝试过非常成功的Rcpp实现,因为R中的这些矩阵产品已经使用了非常高效的代码。
对如何更快地做这件事有什么建议吗?
更新
在阅读了答案后,我尝试了在这个帖子中提出的解决方案,它依赖于QR/SVD/Cholesky因式分解来计算hat矩阵。然而,car::Anova计算所有p=30个矩阵的速度似乎仍然比我只计算一个(s =1)快!例如,n= 5000,q= 10:
Unit: milliseconds
expr min lq mean median uq max neval
ME 1137.5692 1202.9888 1257.8979 1251.6834 1318.9282 1398.9343 10
QR 1005.9082 1031.9911 1084.5594 1037.5659 1095.7449 1364.9508 10
SVD 1026.8815 1065.4629 1152.6631 1087.9585 1241.4977 1446.8318 10
Chol 969.9089 1056.3093 1115.9608 1102.1169 1210.7782 1267.1274 10
CAR 205.1665 211.8523 218.6195 214.6761 222.0973 242.4617 10更新2
目前最好的解决方案是检查car::Anova 代码 (即函数car:::Anova.III.mlm和随后的car:::linearHypothesis.mlm),并重新实现它们,以计算预测器的子集,而不是所有的预测器。
car的相关代码如下(我跳过了检查,并简化了一点):
B <- coef(fit) # Model coefficients
M <- model.matrix(fit) # Model matrix M
V <- solve(crossprod(M)) # M'M
p <- ncol(M) # Number of predictors in M
I.p <- diag(p) # Identity (p x p)
terms <- labels(terms(fit)) # terms (add intercept)
terms <- c("(Intercept)", terms)
n.terms <- length(terms)
assign <- fit$assign # assignation terms <-> p variables
SSP <- as.list(rep(0, n.terms)) # Initialize empty list for sums of squares cross-product matrices
names(SSP) <- terms
for (term in 1:n.terms){
subs <- which(assign == term - 1)
L <- I.p[subs, , drop = FALSE]
SSP[[term]] <- t(L %*% B) %*% solve(L %*% V %*% t(L)) %*% (L %*% B)
}那么,这只是一个选择子集的问题。
回答 1
Stack Overflow用户
发布于 2020-10-26 10:20:50
这一行和H1下面类似的行可能会得到改进:
H <- tcrossprod(tcrossprod(X, solve(crossprod(X))), X)一般的想法是,您应该很少使用solve(Y) %*% Z,因为它与solve(Y, Z)相同,但速度较慢。我还没有完全扩展您的tcrossprod调用,以了解H和H1表达式的最佳等效表达式是什么。
您还可以查看这个问题https://stats.stackexchange.com/questions/139969/speeding-up-hat-matrices-like-xxx-1x-projection-matrices-and-other-as,以了解通过QR分解完成它的描述。
https://stackoverflow.com/questions/64534242
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号