
用R计算欧氏距离
用R计算欧氏距离
提问于 2020-10-17 10:32:49
我有数据,其中行是点,列是坐标x,y,z。
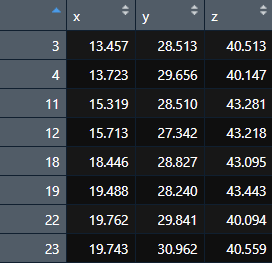
我想计算几个点之间的欧几里德距离,如3-4,11-12,18-19等等.例如,我不需要3到11,12,18之间的距离。问题是,我必须分析1074个有1000行或更多行的表,所以我正在寻找一种自动实现的方法,也许考虑到我想要计算奇数和偶数之间的距离。我不太关心输出格式,但请考虑,在我只选择距离<3.2之后,数据格式将是很好的。
谢谢!:*
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-10-17 10:48:26
像这样的事怎么样:
首先,我要做一些假数据
set.seed(4304)
df <- data.frame(
x = runif(1000, -1, 1),
y = runif(1000, -1, 1),
z = runif(1000, -1,1)
)将值序列从1到数据集的行数按2s排列。
s <- seq(1, nrow(df), by=2)使用sapply()来确定每对点之间的距离。
out <- sapply(s, function(i){
sqrt(sum((df[i,] - df[(i+1), ])^2))
})将距离组织成一个数据框架
res <- data.frame(
pair = paste(rownames(df)[s], rownames(df)[(s+1)], sep="-"),
dist=out)
head(res)
# pair dist
# 1 1-2 1.379992
# 2 3-4 1.303511
# 3 5-6 1.242302
# 4 7-8 1.257228
# 5 9-10 1.107484
# 6 11-12 1.392247Stack Overflow用户
发布于 2020-10-17 11:03:37
下面是一个函数,它可以应用于保存数据的data.frame或矩阵。
DistEucl <- function(X){
i <- cumsum(seq_len(nrow(X)) %% 2 == 1)
sapply(split(X, i), function(Y){
sqrt(sum((Y[1, ] - Y[2, ])^2))
})
}
DistEucl(df1)
# 1 2 3 4
#1.229293 1.234273 1.245567 1.195319 对于DaveArmstrong's answer中的数据,除了上面函数的返回值中有一个name属性外,结果是相同的。
out2 <- DistEucl(df)
all.equal(out, out2)
#[1] "names for current but not for target"
identical(out, unname(out2))
#[1] TRUE问题中的数据
x <- c(13.457, 13.723, 15.319, 15.713, 18.446, 19.488, 19.762, 19.743)
y <- c(28.513, 29.656, 28.510, 27.342, 28.827, 28.24, 29.841, 30.942)
z <- c(40.513, 40.147, 43.281, 43.218, 43.095, 43.443, 40.094, 40.559)
df1 <- data.frame(x, y, z)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64401468
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号