
为更大的数据创建指标矩阵?
为更大的数据创建指标矩阵?
提问于 2020-10-17 08:13:54
我有以下数据:
movies.head()
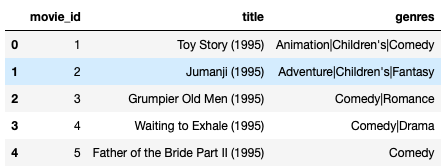
并希望建立一个基于其类型的分类矩阵。最终结果应该如下所示:

我知道如何用一种缓慢的方式来做,那就是:
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
genres = pd.unique(all_genres)
genres产出如下:
array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
'Romance', 'Drama', 'Action', 'Crime', 'Thriller', 'Horror',
'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
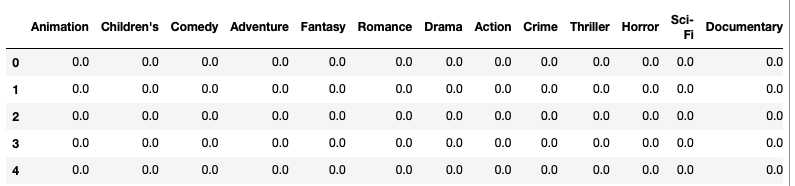
'Western'], dtype=object)创建零矩阵并将其列重命名为类型:
zero_matrix = np.zeros((len(movies), len(genres)))
dummies = pd.DataFrame(zero_matrix, columns=genres)
dummies.head()产出如下:
将movies.genres转换为分类矩阵:
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split('|'))
dummies.iloc[i, indices] = 1
movies_windic = movies.join(dummies.add_prefix('Genre'))
movies_windic.iloc[0:2]产出如下:

上面的代码是从第二版第213,214页中复制的。
让我恼火的是代码中有关其性能的警告,即
对于大得多的数据,这种具有多个成员关系的指标变量的构造不是特别快。最好是编写一个直接写入NumPy数组的低级函数,然后将结果封装到一个DataFrame中。
有人能给我一个指针吗?如何用较低级别的函数来完成它,这样它就能工作得更快?提前谢谢你。
回答 1
Stack Overflow用户
发布于 2020-10-17 11:01:00
让我们生成一些随机数据:
import pandas as pd
df = pd.DataFrame({"Movie_number": [1, 2, 3, 4, 5], "genres": ["A|B|C", "B", "B|C", "C", "A|C"]})
print(df) Movie_number genres
0 1 A|B|C
1 2 B
2 3 B|C
3 4 C
4 5 A|C我想出了一个可怕的解决方案:
newdf = pd.concat([df, pd.get_dummies(df['genres'].str.split('|').explode(), prefix="genre")], axis=1).groupby(["Movie_number", "genres"]).sum().reset_index()
print(newdf) Movie_number genres genre_A genre_B genre_C
0 1 A|B|C 1 1 1
1 2 B 0 1 0
2 3 B|C 0 1 1
3 4 C 0 0 1
4 5 A|C 1 0 1解释:
首先,我们使用基于"genres"分离器的|列爆炸:
>>> df['genres'].str.split('|').explode()
0 A
0 B
0 C
1 B
2 B
2 C
3 C
4 A
4 C
Name: genres, dtype: object然后用pd.get_dummies将这些变量转换为指示变量。
>>> pd.get_dummies(df['genres'].str.split('|').explode(), prefix="genre")
genre_A genre_B genre_C
0 1 0 0
0 0 1 0
0 0 0 1
1 0 1 0
2 0 1 0
2 0 0 1
3 0 0 1
4 1 0 0
4 0 0 1在此之后,我们将其与原始数据rows连接起来,最后将行与groupby和sum合并。
>>> pd.concat([df, pd.get_dummies(df['genres'].str.split('|').explode(), prefix="genre")],axis=1).groupby(["Movie_number", "genres"]).sum().reset_index()
Movie_number genres genre_A genre_B genre_C
0 1 A|B|C 1 1 1
1 2 B 0 1 0
2 3 B|C 0 1 1
3 4 C 0 0 1
4 5 A|C 1 0 1尽管它并不是很低,但我认为它肯定比使用for循环更快。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64400363
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号