
python,列上的字符串操作
from datatable import dt, f, g, by, update, join, sort
tt = dt.Frame({'a' : ['A1','A2','A3'], 'b':[100,200,300]})
print(tt)
| a b
-- + -- ---
0 | A1 100
1 | A2 200
2 | A3 300
[3 rows x 2 columns]如何删除a 列中的“A”,并将其作为datatable方式中的一个数字分配给新列“c”?
在pandas的帮助下,它会是这样的
tt['c'] = tt.to_pandas()['a'].str.replace('A','').astype(int)datatable本机版本不能完全工作。
tt[:, update(c = [int(x.replace('A','')) for x in f.a])]
TypeError: 'datatable.FExpr' object is not iterable顺便问一下,对于一个经常使用蟒蛇熊猫和R data.table的用户来说,是否有一本高级/完整的食谱可以帮助从R data.table过渡到py-datatable?网站上有一个页面,但还不够。
回答 3
Stack Overflow用户
发布于 2020-10-13 01:36:03
这里有一个不太适合扩展的黑客:
步骤1:将a列转储到本机python并创建值的元组:
tuples = [(entry[0], entry[-1]) for entry in tt['a'].to_list()[0]]步骤2:克林丁返回到tt框架:
tt.cbind(dt.Frame(tuples))
tt
a b C0 C1
0 A1 100 A 1
1 A2 200 A 2
2 A3 300 A 3如果您只需要A,那么您可以使用下面的代码,它仍然不能很好地缩放(假设您在列中有空值),并且非常粗糙(我们必须索引到列表中才能得到我们想要的):
tt["A_only"] = dt.Frame([entry[0] for entry in tt['a'].to_list()[0]])
tt
a b A_only
0 A1 100 A
1 A2 200 A
2 A3 300 A如前所述,这样做的规模并不大。此外,它没有提供datatable所要达到的速度。
目前,datatable没有很好的字符串操作支持(我认为库维护人员目前正在处理这个问题,以及其他一些要求的特性)
Stack Overflow用户
发布于 2021-07-03 13:43:02
我知道这是一个老问题,但如果有人还在寻找这个问题--在刚刚发布的1.0.0中,我们可以这样做:
tt = dt.Frame({'a' : ['A1','A2','A3'], 'b':[100,200,300]})
tt["A_only"] = tt[:, f.a[0:1]]
tt["num_only"] = tt[:, f.a[1:]]
tt["num_only"] = dt.Type.int8 # Change the type of the column to `int`
tt.ltypes上面使用字符串列的切片,即依赖于固定的格式。正则表达式也有一个.re部分,但我只看到了match,而没有看到extract。
Stack Overflow用户
发布于 2020-10-12 08:06:55
这是我为了得到你想要的而做的一次黑客攻击。我仍然在学习数据,所以请容忍我,而我完全投入其中。
首先,将datatable转换为dataframe。执行前面列出的操作,然后将dataframe转换回datatable。现在,您有了一个具有所需结果的datatable。
所以我就是这么做的。
from datatable import dt, f, g, by, update, join, sort
tt = dt.Frame({'a' : ['A1','A2','A3'], 'b':[100,200,300]})
df = tt.to_pandas()
df = df.join(df.a.str.extract('([a-zA-Z])([0-9])', expand=True).add_prefix('a'))
df = df.rename(columns = {'a0': 'c', 'a1': 'd'})
tt = dt.Frame(df)
tt这方面的产出如下:
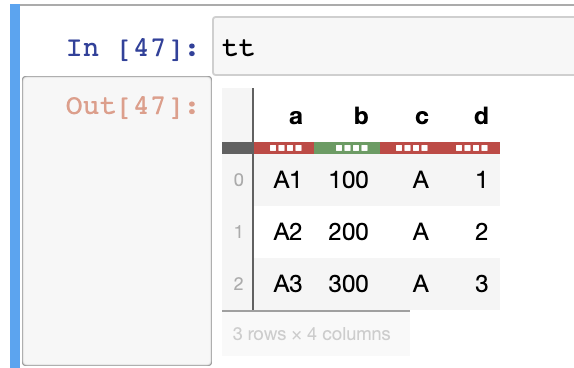
可以拆分该列并重命名该字段。
import pandas as pd
df = pd.DataFrame({'a' : ['A1','A2','A3'], 'b':[100,200,300]})
print (df)
df = df.join(df['a'].str.split(r'(\d.*)', expand=True).add_prefix('a'))
df.drop('a2',axis = 1,inplace=True)
df = df.rename(columns = {'a0': 'c', 'a1': 'd'})
print (df)产出如下:
最初的DataFrame将是:
a b
0 A1 100
1 A2 200
2 A3 300新的DataFrame将如下所示:
a b c d
0 A1 100 A 1
1 A2 200 A 2
2 A3 300 A 3另外,您还可以使用extract和正则表达式来完成它。
import pandas as pd
df1 = pd.DataFrame({'a' : ['A1','A2','A3'], 'b':[100,200,300]})
df1 = df1.join(df1.a.str.extract('([a-zA-Z])([0-9])', expand=True).add_prefix('a'))
df1 = df1.rename(columns = {'a0': 'c', 'a1': 'd'})
print (df1)它会给你同样的结果:
a b
0 A1 100
1 A2 200
2 A3 300在此选项中,它不创建需要删除的附加列。
a b c d
0 A1 100 A 1
1 A2 200 A 2
2 A3 300 A 3https://stackoverflow.com/questions/64312612
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号