
用海运散点图截断y轴值
我有一个问题,绘制大的CSV文件的Y轴值从1到20+百万不等。我现在面临两个问题。
- Y轴没有显示它应该显示的所有值.当使用原始数据时,它显示高达600万,而不是显示高达2000万的所有数据。在下面的示例数据(较小的数据)中,它只显示第一个Y轴值,而不显示任何其他值。
- 在label部分中,由于我使用的是色调和样式=名称," name“显示为标签标题和内部项。
问题:
- 有人能给我一个样本或帮助我回答如何显示所有的Y轴值吗?我怎么才能把它修好让所有的Y值都显示出来?
- 如何在不去掉散点点的形状和颜色的情况下,去掉标签区域下的“名称”?
(请告诉我是否有任何来源,或者这个问题是在另一个帖子上回答的,而不是重复的。)还请告诉我,如果我有任何语法/拼写问题,我需要修复。(谢谢!)
下面的可以找到我用来绘制图形和示例数据的函数.
def test_graph (file_name):
data_file = pd.read_csv(file_name, header=None, error_bad_lines=False, delimiter="|", index_col = False, dtype='unicode')
data_file.rename(columns={0: 'name',
1: 'date',
2: 'name3',
3: 'name4',
4: 'name5',
5: 'ID',
6: 'counter'}, inplace=True)
data_file.date = pd.to_datetime(data_file['date'], unit='s')
norm = plt.Normalize(1,4)
cmap = plt.cm.tab10
df = pd.DataFrame(data_file)
# Below creates and returns a dictionary of category-point combinations,
# by cycling over the marker points specified.
points = ['o', 'v', '^', '<', '>', '8', 's', 'p', 'H', 'D', 'd', 'P', 'X']
mult = len(df['name']) // len(points) + (len(df['name']) % len(points) > 0)
markers = {key:value for (key, value)
in zip(df['name'], points * mult)} ; markers
sc = sns.scatterplot(data = df, x=df['date'], y=df['counter'], hue = df['name'], style = df['name'], markers = markers, s=50)
ax.set_autoscaley_on(True)
ax.set_title("TEST", size = 12, zorder=0)
plt.legend(title="Names", loc='center left', shadow=True, edgecolor = 'grey', handletextpad = 0.1, bbox_to_anchor=(1, 0.5))
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(100))
plt.xlabel("Dates", fontsize = 12, labelpad = 7)
plt.ylabel("Counter", fontsize = 12)
plt.grid(axis='y', color='0.95')
fig.autofmt_xdate(rotation = 30)
fig = plt.figure(figsize=(20,15),dpi=100)
ax = fig.add_subplot(1,1,1)
test_graph(file_name)
plt.savefig(graph_results + "/Test.png", dpi=100)
# Prevents to cut-off the bottom labels (manually) => makes the bottom part bigger
plt.gcf().subplots_adjust(bottom=0.15)
plt.show()样本数据
namet1|1582334815|ai1|ai1||150|101
namet1|1582392415|ai2|ai2||142|105
namet2|1582882105|pc1|pc1||1|106
namet2|1582594106|pc1|pc1||1|123
namet2|1580592505|pc1|pc1||1|141
namet2|1580909305|pc1|pc1||1|144
namet3|1581974872|ai3|ai3||140|169
namet1|1581211616|ai4|ai4||134|173
namet2|1582550907|pc1|pc1||1|179
namet2|1582608505|pc1|pc1||1|185
namet4|1581355640|ai5|ai5|bcu|180|298466
namet4|1582651641|pc2|pc2||233|298670
namet5|1582406860|ai6|ai6|bcu|179|298977
namet5|1580563661|pc2|pc2||233|299406
namet6|1581283626|qe1|q0/1|Link to btse1/3|51|299990
namet7|1581643672|ai5|ai5|bcu|180|300046
namet4|1581758842|ai6|ai6|bcu|179|300061
namet6|1581298027|qe2|q0/2|Link to btse|52|300064
namet1|1582680415|pc2|pc2||233|300461
namet6|1581744427|pc3|p90|Link to btsi3a4|55|6215663
namet6|1581730026|pc3|p90|Link to btsi3a4|55|6573348
namet6|1582190826|qe2|q0/2|Link to btse|52|6706378
namet6|1582190826|qe1|q0/1|Link to btse1/3|51|6788568
namet1|1581974815|pc2|pc2||233|6895836
namet4|1581974841|pc2|pc2||233|7874504
namet6|1582176427|qe1|q0/1|Link to btse1/3|51|9497687
namet6|1582176427|qe2|q0/2|Link to btse|52|9529133
namet7|1581974872|pc2|pc2||233|9573450
namet6|1582162027|pc3|p90|Link to btsi3a4|55|9819491
namet6|1582190826|pc3|p90|Link to btsi3a4|55|13494946
namet6|1582176427|pc3|p90|Link to btsi3a4|55|19026820我正在获得的结果:
大数据:
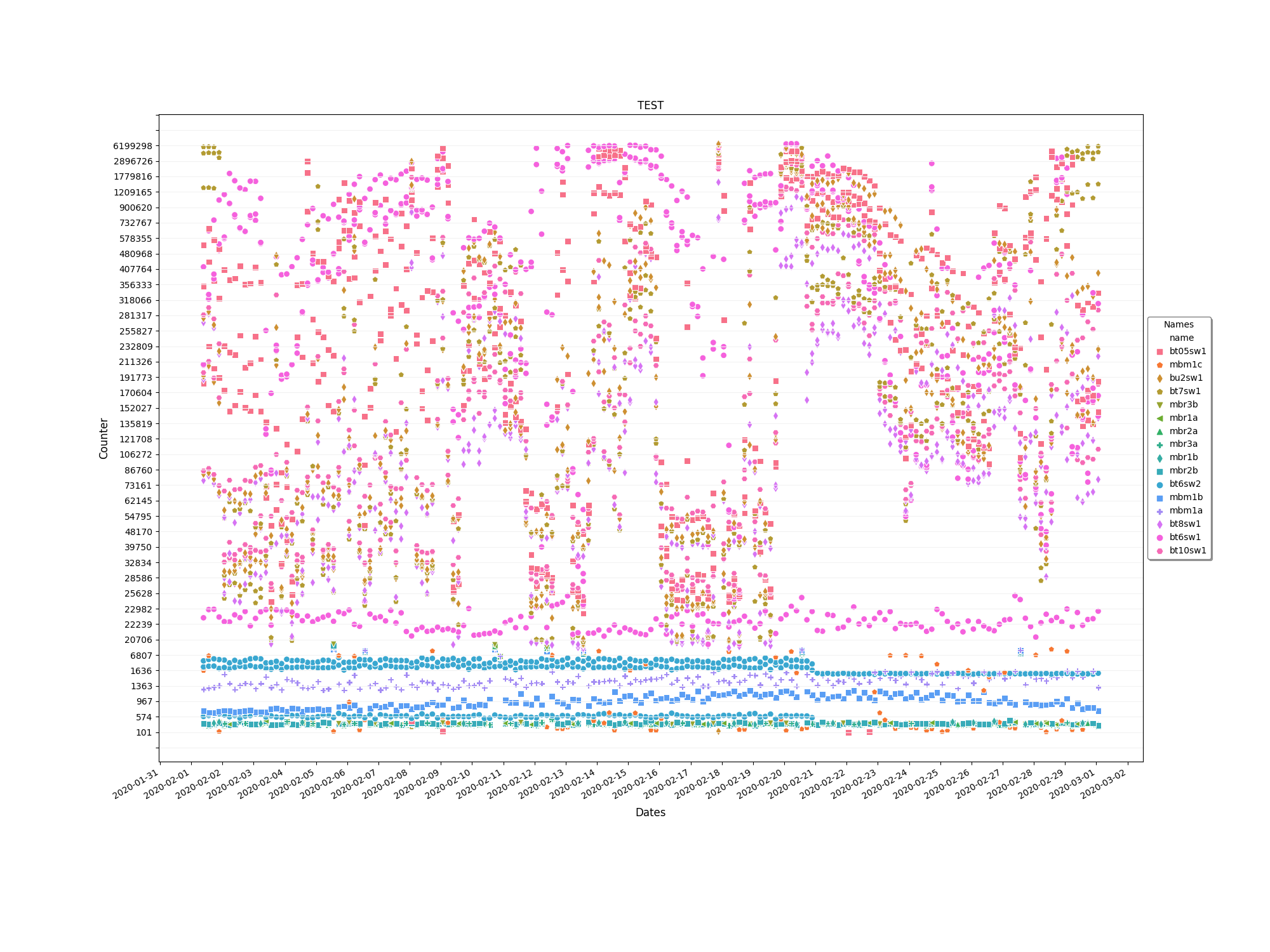
小数据:
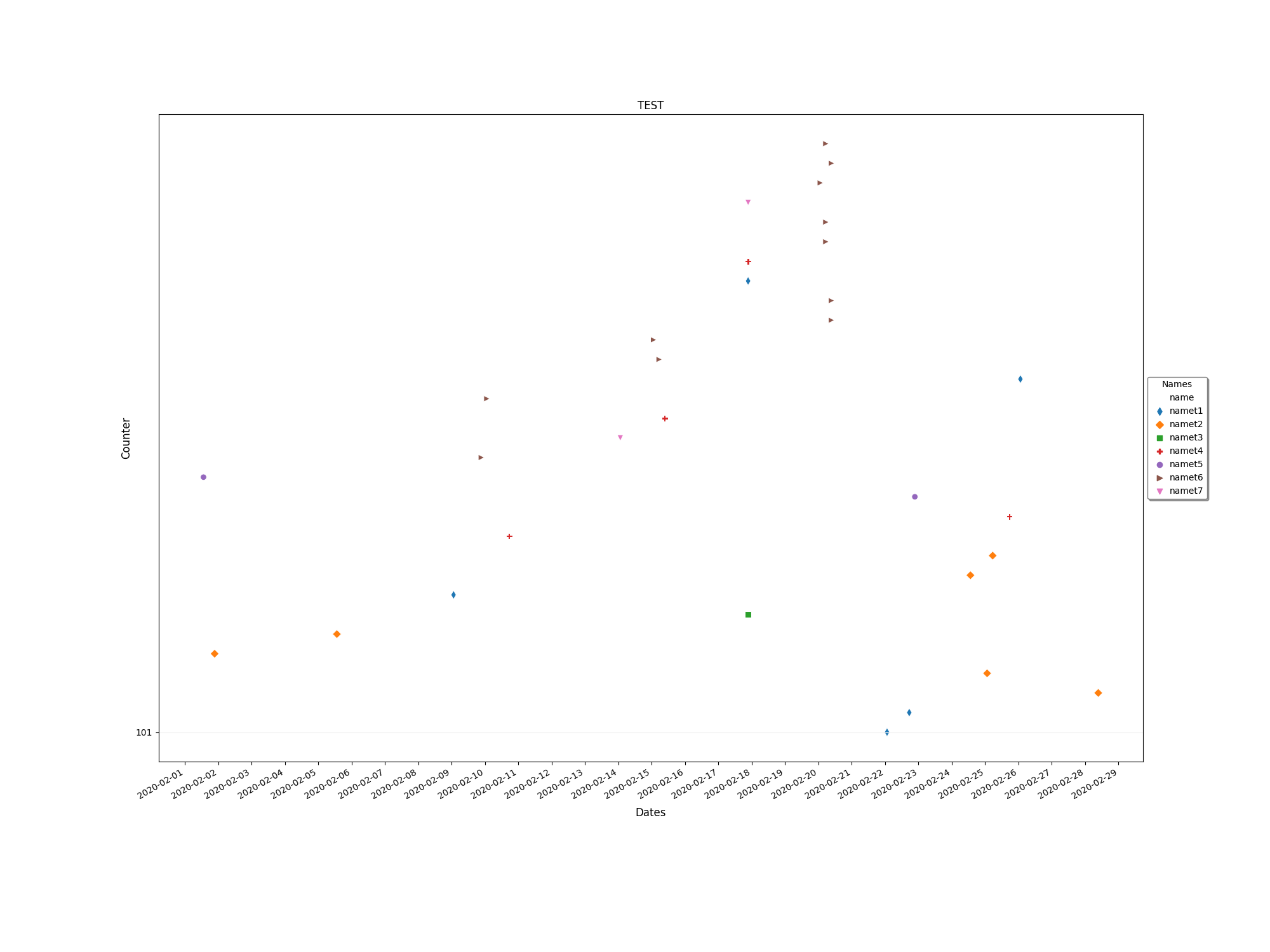
更新图 更新图
{kind=link}
回答 1
Stack Overflow用户
发布于 2020-10-07 16:04:26
首先,您的帖子有一些改进:您缺少了导入语句。
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
import seaborn as sns线
df = pd.DataFrame(data_file)没有必要,因为data_file已经是一个DataFrame。线
points = ['o', 'v', '^', '<', '>', '8', 's', 'p', 'H', 'D', 'd', 'P', 'X']
mult = len(df['name']) // len(points) + (len(df['name']) % len(points) > 0)
markers = {key:value for (key, value)
in zip(df['name'], points * mult)}不要像您所期望的那样在points中循环,也许可以按照建议的这里使用itertools。同时,设置类似于
ax.yaxis.set_major_locator(ticker.MultipleLocator(100))如果您的数据跨度从0到2000万,那么每100个数据可能太多了,请考虑用1000000替换100。
我能重现你的第一个问题。使用df.dtypes,我发现列counter存储为object类型。添加行
df['counter']=df['counter'].astype(int)帮我解决了你的第一个问题。但是我不能复制你的第二期。下面是生成的情节对我来说的样子:
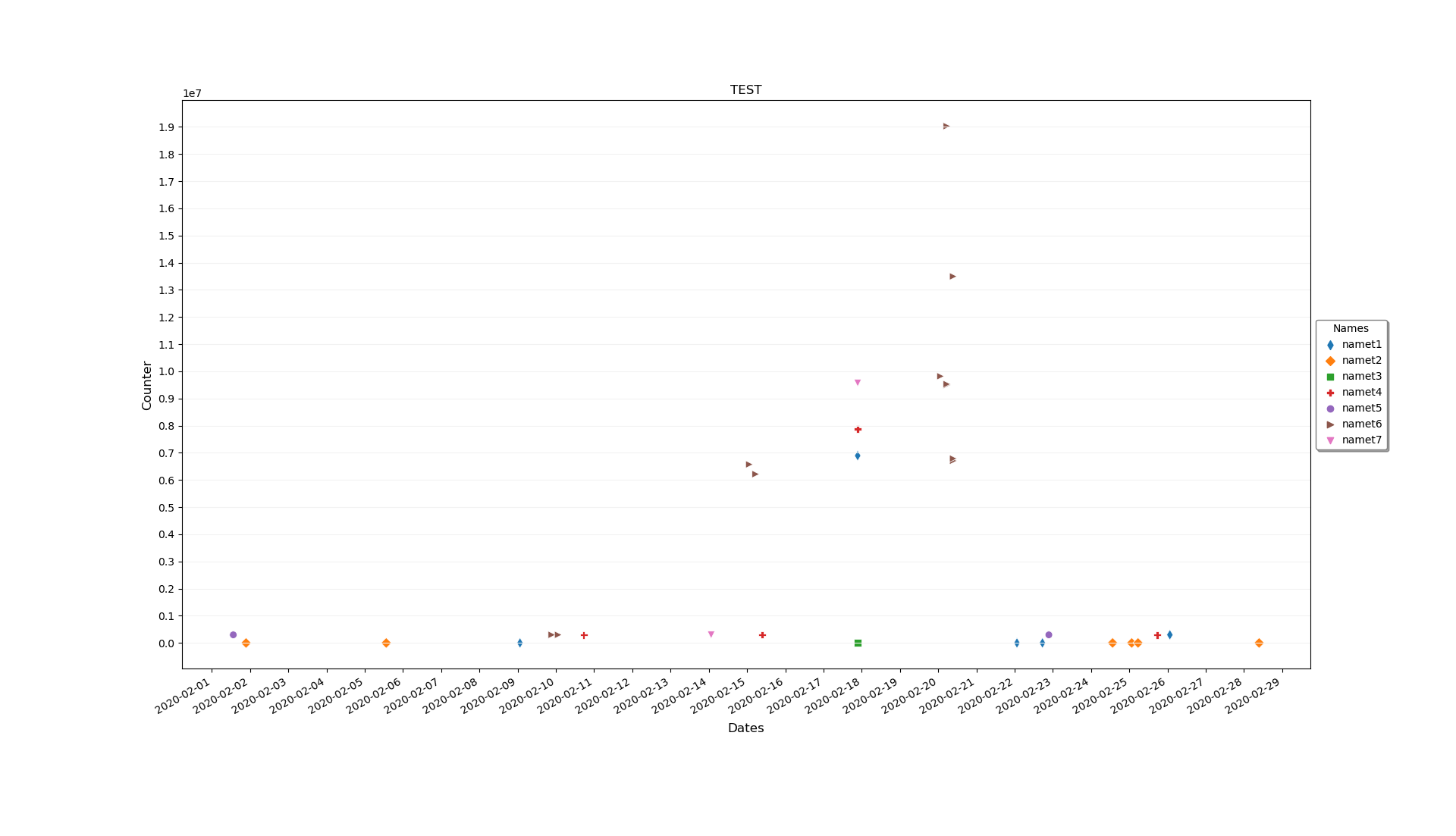
您是否尝试过将所有软件包更新为最新版本?
编辑:作为对您的评论的后续,您还可以通过替换1在您的小区中调整xticks的数量
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))将我的所有建议和删除看似不必要的函数定义结合起来,我的代码版本如下:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
import seaborn as sns
import itertools
fig = plt.figure()
ax = fig.add_subplot()
df = pd.read_csv(
'data.csv',
header = None,
error_bad_lines = False,
delimiter = "|",
index_col = False,
dtype = 'unicode')
df.rename(columns={0: 'name',
1: 'date',
2: 'name3',
3: 'name4',
4: 'name5',
5: 'ID',
6: 'counter'}, inplace=True)
df.date = pd.to_datetime(df['date'], unit='s')
df['counter'] = df['counter'].astype(int)
points = ['o', 'v', '^', '<', '>', '8', 's', 'p', 'H', 'D', 'd', 'P', 'X']
markers = itertools.cycle(points)
markers = list(itertools.islice(markers, len(df['name'].unique())))
sc = sns.scatterplot(
data = df,
x = 'date',
y = 'counter',
hue = 'name',
style = 'name',
markers = markers,
s = 50)
ax.set_title("TEST", size = 12, zorder=0)
ax.legend(
title = "Names",
loc = 'center left',
shadow = True,
edgecolor = 'grey',
handletextpad = 0.1,
bbox_to_anchor = (1, 0.5))
ax.xaxis.set_major_locator(ticker.MultipleLocator(10))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1000000))
ax.minorticks_off()
ax.set_xlabel("Dates", fontsize = 12, labelpad = 7)
ax.set_ylabel("Counter", fontsize = 12)
ax.grid(axis='y', color='0.95')
fig.autofmt_xdate(rotation = 30)
plt.gcf().subplots_adjust(bottom=0.15)
plt.show()https://stackoverflow.com/questions/64246521
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号