
实现特性-记忆问题?
实现特性-记忆问题?
提问于 2020-10-06 21:55:31
我正在尝试干的我的代码,我第一次用traits来增强我的enums。
我想要做的是:对于给定的字符串数组,查找所有匹配至少一个关键字(不区分大小写)的枚举。
下面的代码似乎运行良好,但我认为当方法getSymbolFromIndustries被调用数千次时,它会产生内存泄漏。
下面是运行大约10分钟后从VisualVM获取的信息,列Live在每次快照之后总是在增加,并且与第二行相比,条目的数量是如此巨大……
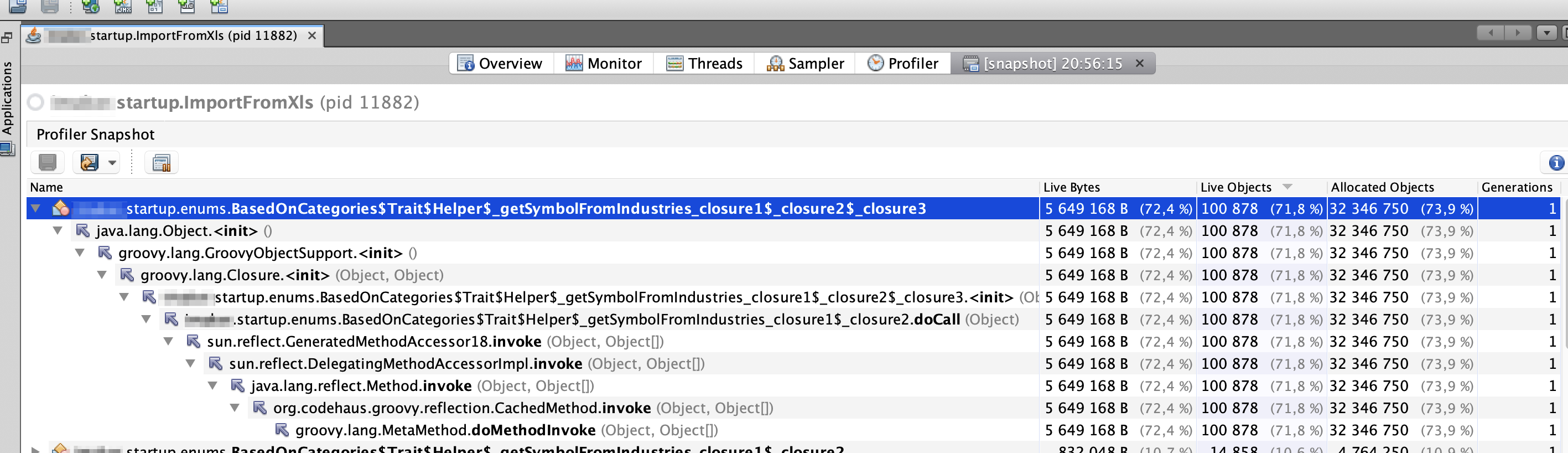
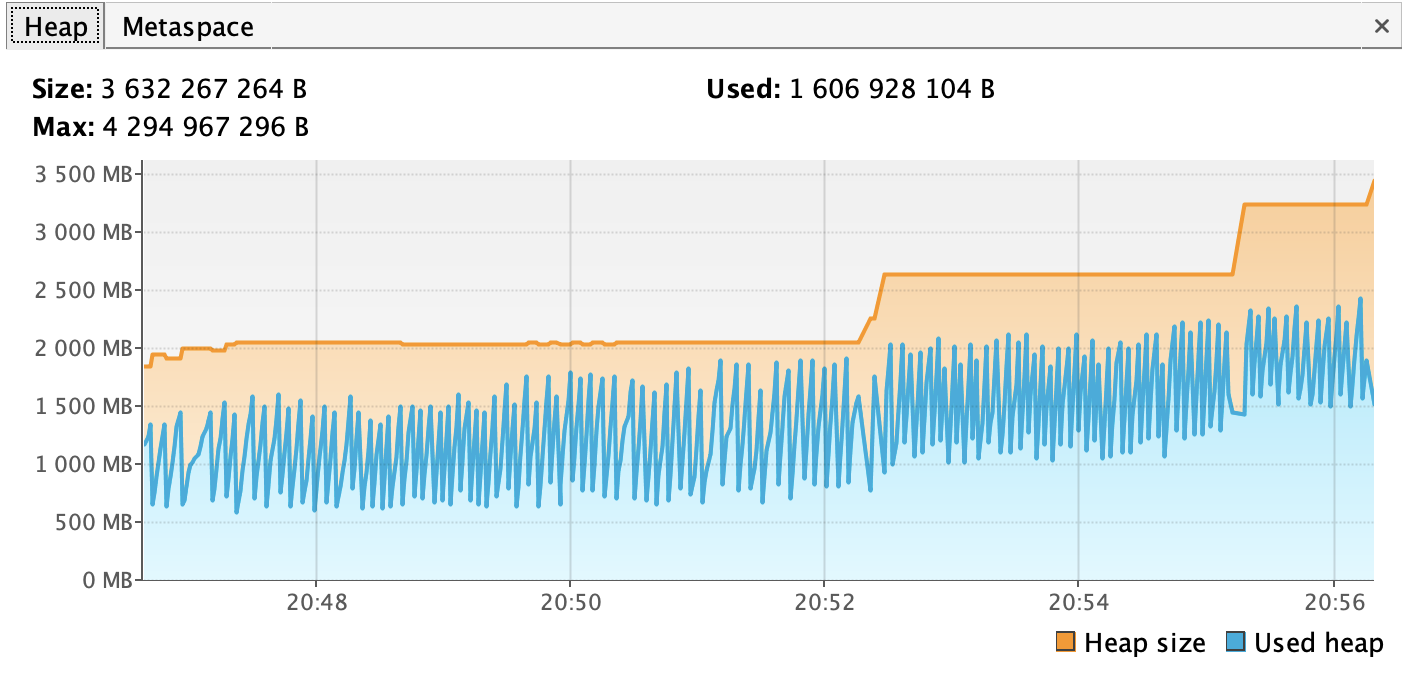
我的堆大小也一直在增加..。
特点:
trait BasedOnCategories {
String[] categories
static getSymbolFromIndustries(Collection<String> candidates) {
values().findAll {
value -> !value.categories.findAll {
categorie -> candidates.any {
candidate -> categorie.equalsIgnoreCase(candidate)
}
}
.unique()
.isEmpty()
}
}
}实现trait的多个枚举之一
enum KTC implements BasedOnCategories, BasedOnValues {
KTC_01([
'industries': ['Artificial Intelligence','Machine Learning','Intelligent Systems','Natural Language Processing','Predictive Analytics','Google Glass','Image Recognition', 'Apps' ],
'keywords': ['AI','Voice recognition']
]),
// ... more values
KTC_43 ([
'industries': ['Fuel','Oil and Gas','Fossil Fuels'],
'keywords': ['Petroleum','Oil','Petrochemicals','Hydrocarbon','Refining']
]),
// ... more values
KTC_60([
'industries': ['App Discovery','Apps','Consumer Applications','Enterprise Applications','Mobile Apps','Reading Apps','Web Apps','App Marketing','Application Performance Management', 'Apps' ],
'keywords': ['App','Application']
])
KTC(value) {
this.categories = value.industries
this.keywords = value.keywords
}我的数据驱动测试
def "GetKTCsFromIndustries"(Collection<String> actual, Enum[] expected) {
expect:
assert expected == KTC.getSymbolFromIndustries(actual)
where:
actual | expected
[ 'Oil and Gas' ] | [KTC.KTC_43]
[ 'oil and gas' ] | [KTC.KTC_43]
[ 'oil and gas', 'Fossil Fuels' ] | [KTC.KTC_43]
[ 'oil and gas', 'Natural Language Processing' ] | [KTC.KTC_01, KTC.KTC_43]
[ 'apps' ] | [KTC.KTC_01, KTC.KTC_60]
[ 'xyo' ] | []
}我的问题:
- 如果有人有线索帮我解决这些漏洞..。
- 是否有更优雅的方法来编写
getSymbolFromIndustries方法?
谢谢。
回答 1
Stack Overflow用户
发布于 2020-10-07 09:36:18
不确定性能问题,但我会像这样重新设计你的特质:
https://groovyconsole.appspot.com/script/5205045624700928
trait BasedOnCategories {
Set<String> categories
void setCategories( Collection<String> cats ) {
categories = new HashSet( cats*.toLowerCase() ).asImmutable()
}
@groovy.transform.Memoized
static getSymbolFromIndustries(Collection<String> candidates) {
def lowers = candidates*.toLowerCase()
values().findAll{ value -> !lowers.disjoint( value.categories ) }
}
}现在剩下的上下文
trait BasedOnValues {
Set<String> keywords
}
enum KTC implements BasedOnCategories, BasedOnValues {
KTC_01([
'industries': ['Artificial Intelligence','Machine Learning','Intelligent Systems','Natural Language Processing','Predictive Analytics','Google Glass','Image Recognition'],
'keywords': ['AI','Voice recognition']
]),
// ... more values
KTC_43 ([
'industries': ['Fuel','Oil and Gas','Fossil Fuels'],
'keywords': ['Petroleum','Oil','Petrochemicals','Hydrocarbon','Refining']
]),
// ... more values
KTC_60([
'industries': ['App Discovery','Apps','Consumer Applications','Enterprise Applications','Mobile Apps','Reading Apps','Web Apps','App Marketing','Application Performance Management'],
'keywords': ['App','Application']
])
KTC(value) {
this.categories = value.industries
this.keywords = value.keywords
}
}
// some tests
[
[ [ 'Oil and Gas' ], [KTC.KTC_43] ],
[ [ 'oil and gas' ], [KTC.KTC_43] ],
[ [ 'oil and gas', 'Fossil Fuels' ], [KTC.KTC_43] ],
[ [ 'oil and gas', 'Natural Language Processing' ], [KTC.KTC_01, KTC.KTC_43] ],
[ [ 'xyo' ], [] ],
].each{
assert KTC.getSymbolFromIndustries( it[ 0 ] ) == it[ 1 ]
}然后衡量业绩
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64234339
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号