
正则表达式将所有内容替换为空白,但模式除外(dplyr、stringr)。
正则表达式将所有内容替换为空白,但模式除外(dplyr、stringr)。
提问于 2020-09-29 01:20:21
我有一个如下所示的数据框架(示例数据):
myCars <- structure(list(Engine_Information = c("Ford 3.5L 6 Cylinder 355 hp 350 ft-lbs Turbo",
"Ford 5.4L 8 cylinder 310 hp 365 ft-lbs FFV", "Audi 3.0L 6 Cylinder 333 hp 325 ft-lbs S-charged",
"Toyota 2.7L 4 Cylinder 159 hp 180 ft-lbs", "Chevrolet 4.3L 6 Cylinder 195 hp 260 ft-lbs",
"Chevrolet 3.0L 6 Cylinder 264 hp 222 ft-lbs FFV", "GMC 3.7L 5 Cylinder 242 hp 242 ft-lbs",
"Volvo 3.2 L 6 cylinder 240 hp 236 ft-lbs", "Hyundai 2.4L 4 Cylinder 198 hp 184 ft-lbs",
"Mercedes-AMG 5.4L 8 Cylinder 500 hp 516 ft-lbs S-Charged")),
row.names = c(1074L, 1923L, 811L, 3378L, 2419L, 2080L, 2995L, 4889L, 1023L, 1368L),
class = "data.frame")使用dplyr和stringr,我想创建一个只包含汽车马力的新列。
下面是我的(尝试)代码:
myCars_HP <- myCars %>%
mutate(HP = Engine_Information) %>%
mutate(HP = str_replace(HP, "^(?![0-9]{3}).*$", ""))regex模式背后的想法是用空格替换所有东西(在新列中),除了前三位数字(这个数字是HP)。
但是,我尝试过的每个regex模式都只返回空白。
我想要的产出是:
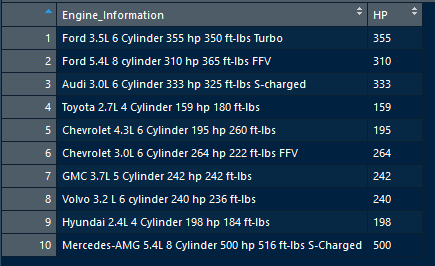
我更喜欢使用base R/dplyr/stringr函数,所以请告诉我是否有更有效的方法来做到这一点。
但最重要的是,我想知道为什么我的regex不起作用,以及什么模式会起作用。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-09-29 01:30:01
您可以提取"hp"字符串之前的数字。
在基本R中,可以使用sub:
myCars$hp <- as.numeric(sub('.*?(\\d+)\\shp.*', '\\1',myCars$Engine_Information))与dplyr/stringr一起使用正前瞻正则表达式。
library(dplyr)
library(stringr)
myCars %>%
mutate(HP = as.numeric(str_extract(Engine_Information, '\\d+(?=\\shp)')))
# Engine_Information HP
#1 Ford 3.5L 6 Cylinder 355 hp 350 ft-lbs Turbo 355
#2 Ford 5.4L 8 cylinder 310 hp 365 ft-lbs FFV 310
#3 Audi 3.0L 6 Cylinder 333 hp 325 ft-lbs S-charged 333
#4 Toyota 2.7L 4 Cylinder 159 hp 180 ft-lbs 159
#5 Chevrolet 4.3L 6 Cylinder 195 hp 260 ft-lbs 195
#6 Chevrolet 3.0L 6 Cylinder 264 hp 222 ft-lbs FFV 264
#7 GMC 3.7L 5 Cylinder 242 hp 242 ft-lbs 242
#8 Volvo 3.2 L 6 cylinder 240 hp 236 ft-lbs 240
#9 Hyundai 2.4L 4 Cylinder 198 hp 184 ft-lbs 198
#10 Mercedes-AMG 5.4L 8 Cylinder 500 hp 516 ft-lbs S-Charged 500页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64111593
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号