
从regex中排除“x”
我正试图从youtube标签的列表中排除“分部”。
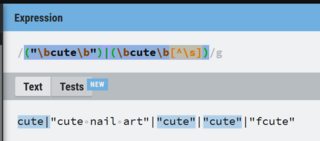
到目前为止,我能够regex选择所有可爱的标签,例如在下面的字符串中
cute|"cute nail art"|"cute"|"cute"|"fcute"
我能准确地突出“可爱”和“可爱”。问题是这个问题。我该怎么摆脱它?
我的regex查询是这个("\bcute\b")|(\bcute\b[^\s])。
我的预期结果是突出可爱和“可爱”。
任何提示都将不胜感激,并感谢您的阅读。
回答 2
Stack Overflow用户
发布于 2020-09-09 08:20:33
假设输入是由|连接的一串标记,并且有些标记以引号括起来,并且您想要标识和标记某个标记,无论是原样还是引号,所需的正则表达式可能如下所示:
(?<=\||^)(cute|"cute")(?=\||$)在这里检查它的作用:https://regex101.com/r/acjM8R/3
裁判官解释说
(?<= # start a positive lookbehind assertion
^ # match the beginning of the string
| # OR
\| # match the character '|' literally (it has a special meaning when not escaped)
) # end of the lookbehind assertion
( # start a capturing group; it is also used to group the alternatives
cute # match the word 'cute' (the tag) as is
| # OR
"cute" # match the word "cute" (the tag) when it is quoted
) # end of the group
(?= # start a positive lookahead assertion
\| # match the character '|' literally (it has a special meaning when not escaped)
| # OR
$ # match the end of the string
) # end of the lookahead assertion片段^|\|匹配字符串的开头(^)或字符| (分隔符)。类似地,片段\||$匹配| (分隔符)或字符串的末尾。
正断言是对前面字符((?<= ... ))或后续字符((?= ... ))的测试,当前匹配点实际上不消耗任何字符。
总之,上面的正则表达式匹配cute或"cute",但只有当它被分隔符|或字符串边界包围时才匹配。
更新
编写(cute|"cute")的另一种方法是(("?)cute\2)。
片段("?)捕获一个可选(?)引号(")。后面跟着实际的标签。片段\2的意思是“与第二个捕获组相同”,在本例中,该捕获组是("?)匹配的文本。
这意味着,如果("?)匹配某项内容(一个引用),\2也必须匹配一个引用。如果("?)匹配空字符串( |和cute之间没有引号),\2也匹配空字符串。
看到它在这里工作:https://regex101.com/r/acjM8R/4/
Stack Overflow用户
发布于 2020-09-09 07:37:31
我想您要做的是使用文字|。因此,您需要像\|一样转义它。
https://stackoverflow.com/questions/63806804
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号