
云数据仓库中使用Wrangler将Avro文件转换为JSON
云数据仓库中使用Wrangler将Avro文件转换为JSON
提问于 2020-08-31 11:02:36
{kind=link}
{kind=link}
{kind=link}
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-09-01 15:06:26
当使用Wrangler进行转换时,GCS源的默认值是format: text和body: string (数据类型);但是,要正确地处理Wrangler中的Avro文件,您需要更改它,需要将格式设置为blob,体数据类型设置为bytes,如下所示:
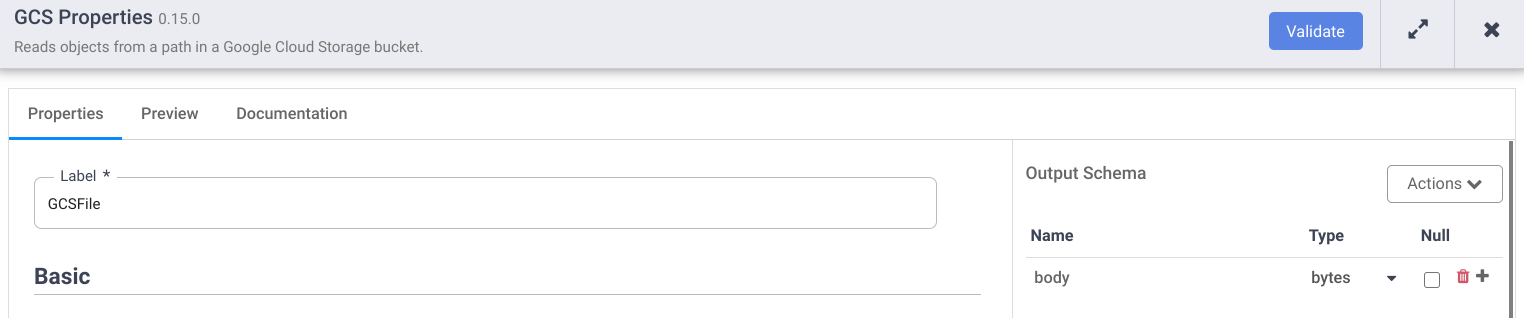
在此之后,管道的预览应该生成输出记录。接下来您可以看到我的工作示例:
- 样本数据
- 转换
- GCS接收器的输入记录预览 (最终输出)
{kind=link}
{kind=link}
{kind=link}
编辑:
您需要将format: blob和输出模式设置为body: bytes,如果您想在Wrangler中将该文件解析为Avro (如前所述),因为它需要二进制格式的文件内容。
另一方面,如果您只想应用过滤器(在Wrangler中),则可以执行以下操作:
- 使用
format: avro,见img打开文件。 - 根据您的Avro文件所具有的字段设置输出模式,在本例中是
name和string数据类型的见img。 - 只在Wrangler上使用过滤器(此处不解析Avro ),见img。
{kind=link}
{kind=link}
{kind=link}
这样,您还可以获得所需的结果。
{kind=link}
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63669583
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号