
打印html标记的子p元素
打印html标记的子p元素
提问于 2020-08-26 13:01:36
我正在使用漂亮的汤打印某些文本从网站外到一个控制台。
我试图打印'p‘标签文本,是’8月‘和'27',但只有'a’标签包含一个子'img‘标签,但出于某种原因,没有任何打印出来。
这是html代码-(我在我想要的红色文本下划线)
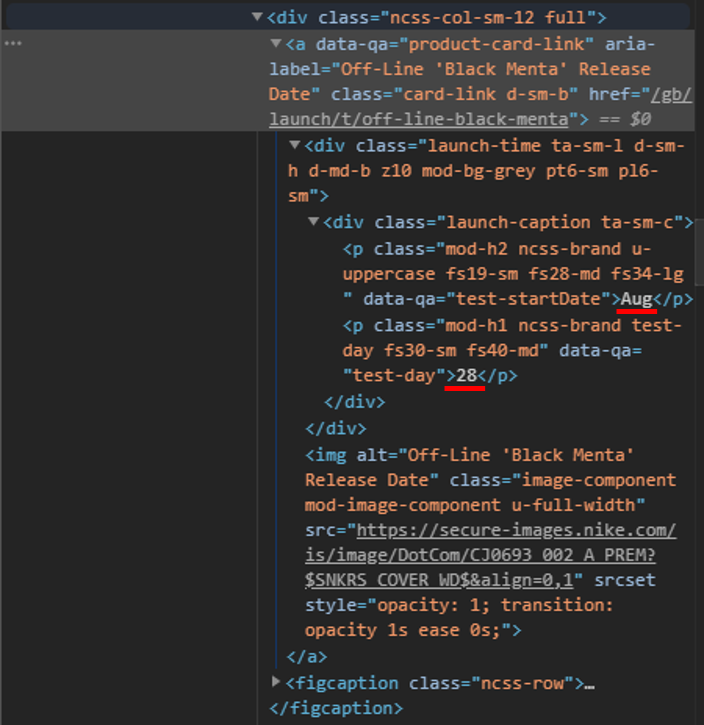
<a data-qa="product-card-link" aria-label="Off-Line 'Black Menta' Release Date" class="card-link d-sm-b" href="/gb/launch/t/off-line-black-menta">
<div class="launch-time ta-sm-l d-sm-h d-md-b z10 mod-bg-grey pt6-sm pl6-sm">
<div class="launch-caption ta-sm-c">
<p class="mod-h2 ncss-brand u-uppercase fs19-sm fs28-md fs34-lg " data-qa="test-startDate">Aug</p>
<p class="mod-h1 ncss-brand test-day fs30-sm fs40-md" data-qa="test-day">28</p>
</div>
</div>
<img alt="Off-Line 'Black Menta' Release Date" class="image-component mod-image-component u-full-width" src="https://secure-images.nike.com/is/image/DotCom/CJ0693_002_A_PREM?$SNKRS_COVER_WD$&align=0,1" srcset="" style="opacity: 1; transition: opacity 1s ease 0s;">
</a>以下是我尝试过的:
for a in soup.find_all('a', class_='card-link d-sm-b'):
if a.find('img'):
for p in a.find_all('p'):
print(p.text)回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-26 16:15:43
您可以使用CSS选择器a.card-link:has(> img):has(p),它将使用包含直接子<img>和<p>标记的class="card-link"来选择所有的<p>标记(<p>标记可以是任何深度的):
from bs4 import BeautifulSoup
txt = '''
<a data-qa="product-card-link" aria-label="Off-Line 'Black Menta' Release Date" class="card-link d-sm-b" href="/gb/launch/t/off-line-black-menta">
<div class="launch-time ta-sm-l d-sm-h d-md-b z10 mod-bg-grey pt6-sm pl6-sm">
<div class="launch-caption ta-sm-c">
<p class="mod-h2 ncss-brand u-uppercase fs19-sm fs28-md fs34-lg " data-qa="test-startDate">Aug</p>
<p class="mod-h1 ncss-brand test-day fs30-sm fs40-md" data-qa="test-day">28</p>
</div>
</div>
<img alt="Off-Line 'Black Menta' Release Date" class="image-component mod-image-component u-full-width" src="https://secure-images.nike.com/is/image/DotCom/CJ0693_002_A_PREM?$SNKRS_COVER_WD$&align=0,1" srcset="" style="opacity: 1; transition: opacity 1s ease 0s;">
</a>'''
soup = BeautifulSoup(txt, 'html.parser')
for a in soup.select('a.card-link:has(> img):has(p)'):
all_p = [p.get_text(strip=True) for p in a.select('p')]
print(all_p)指纹:
['Aug', '28']编辑:要获取产品的日期和名称,可以使用以下脚本:
import requests
from bs4 import BeautifulSoup
url = 'https://www.nike.com/gb/launch?s=upcoming'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
for d in soup.select('div.launch-caption'):
print(d.get_text(strip=True, separator=' '),
d.find_next('h3').get_text(strip=True),
d.find_next('h6').get_text(strip=True))指纹:
Aug 27 Air Jordan 3 Denim
Aug 28 Off-Line Black Menta
Aug 28 Off-Line Vast Grey
Aug 29 Air Max 1 Evergreen Aura
Aug 29 Air Jordan 12 University Gold
Sep 1 ISPA Drifter Split Iron Grey
Sep 1 ISPA Drifter Split Spruce页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63598268
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号