
机器学习模型的部署.数据版本控制
假设在Microsoft上托管的存储库的主分支上有一个发布管道。当在这个分支上完成拉请求时,就会自动生成一个人工制品。单击伪制品时,我们可以看到一个“出处”窗口,该窗口显示用于发布伪制品的代码的确切提交情况(见下图)。
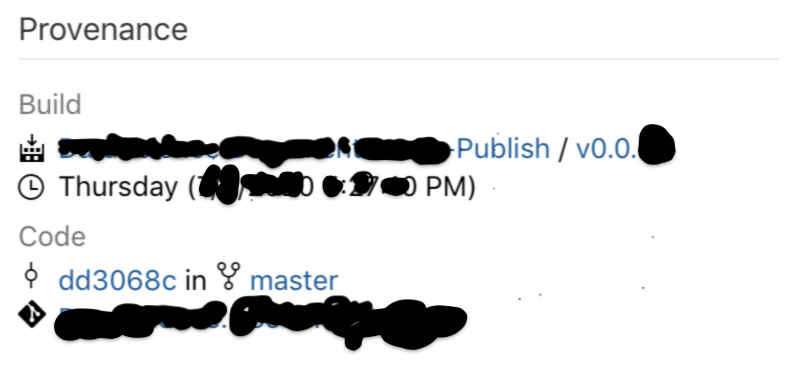
现在假设人工制品不仅是使用代码构建的,而且使用的是大量数据。这就是用训练代码和训练数据创建的机器学习模型的例子。我希望能够将两者的版本链接到人工制品(机器学习模型),理想情况下,该模型是在主服务器上的PR之后自动创建的。
目前,我手动上传伪文件,因此不仅缺少用于生成ML模型的数据的标识符,而且缺少代码的提交id。
有没有一种方法在Azure上自动生产(沉重的)艺术品?是否有一种方法可以跟踪代码的id和用于生成伪制品的数据?我想我需要一个数据版本控制系统+一个存储。这些是由Azure提供的吗?
回答 1
Stack Overflow用户
发布于 2020-07-15 07:07:02
有没有一种方法在Azure上自动生产(沉重的)艺术品?是否有一种方法可以跟踪代码的id和用于生成伪制品的数据?我想我需要一个数据版本控制系统+一个存储。这些是由Azure提供的吗?
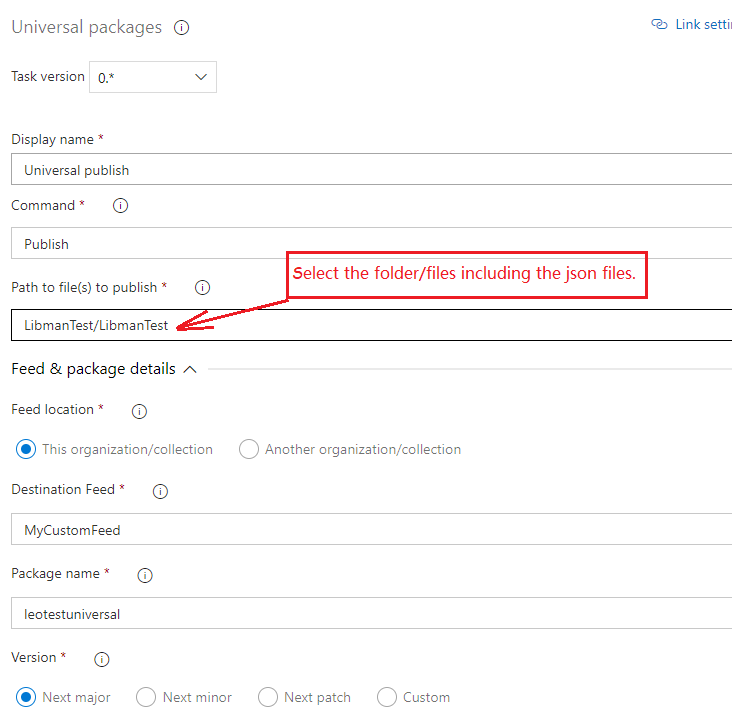
如果我理解您的正确性,您可以尝试使用Universal将那些json文件打包为工件。
作为测试,我们可以使用Universal任务创建和发布工件:
构建完成后,我们可以在提要中获得工件:
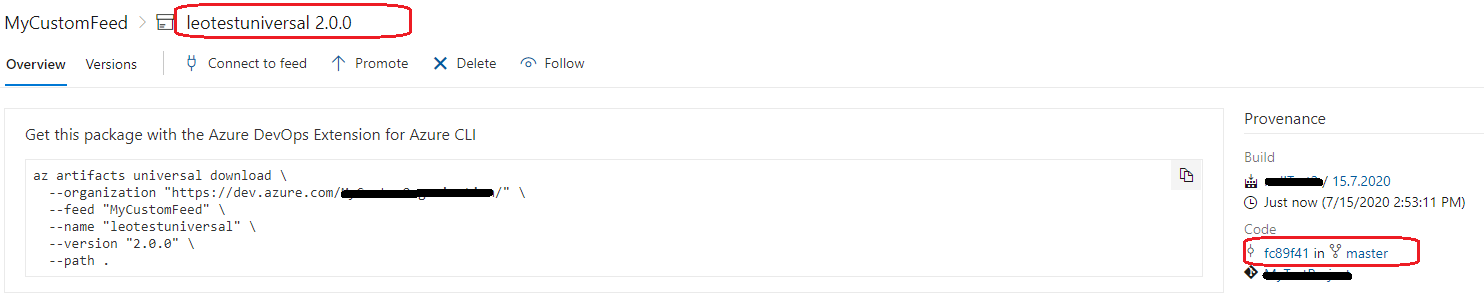
您可以查看此文档在Azure管道中发布和下载通用包和带有Azure DevOps工件的通用包以获得一些详细信息。
https://stackoverflow.com/questions/62896440
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号