
使用GCN-LSTM为图表示的场景生成描述。
给定一个场景,我使用对象检测器检索其中包含的对象。接下来,我通过指定每个一元关系的最可能属性(例如对象Cat和属性"Sitting",这意味着"The cat is sitting")和每个二进制关系的最可能谓词(例如,一对对象[Cup - Table]和谓词"On",这意味着"The cup is on the table"),来识别场景中潜在的一元(一个对象)和二进制(一对对象)的视觉关系(使用专门的分类器)。
所有这些定义的关系都由一个具有以下形式的有向图建模:
- 每个节点表示场景的一个对象(带有其id)。
- 每个定义的一元关系(属性)都由一个循环(一个箭头,从一个节点到自己,带有相应的属性)建模。
- 每个定义的二进制关系都由一个箭头建模,从一个节点(关系的左侧)到另一个节点(关系的右侧),并带有相应的谓词。
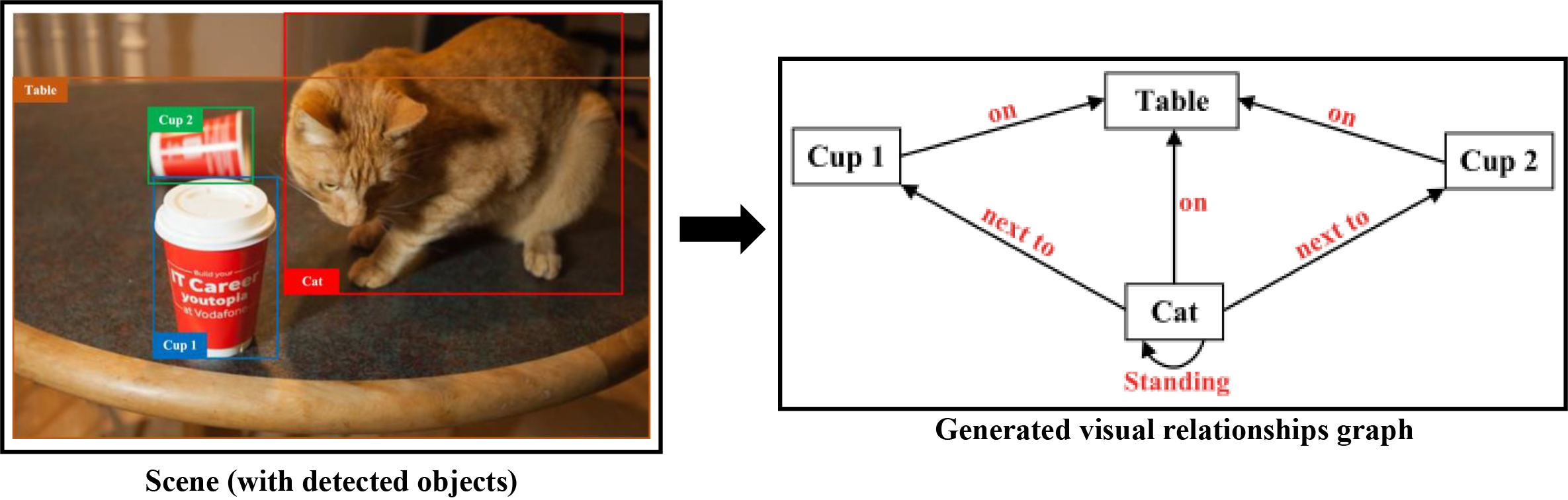
下图显示了从场景构建关系图的示例。后者包含四个对象:"cup 1"、"cup 2"、"cat"和"table"。定义的关系是:
- 一元关系(只有一个):用于
"cat"对象("standing")。 - 二进制关系(5个关系):三个与谓词
"on"([Cat - Table],[Cup 1 - Table],[Cup 2 - Table]),两个与谓词"next to"([Cat - Cup 1],[Cat - Cup 2])。
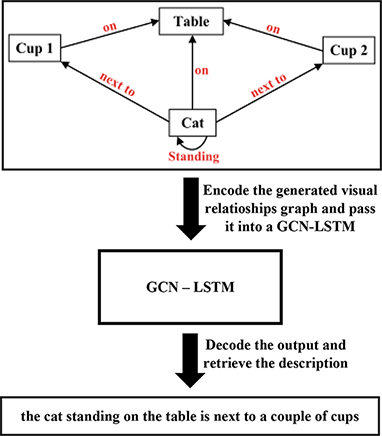
目标是训练一个GCN-LSTM,它接收(输入)先前的图,并返回(在输出中)一个描述(它对应于这个图,因此对应于最初的场景)。
这个GCN-LSTM的训练是通过为每个训练场景创建它的图形(输入)和输出是它的描述(段落)来完成的。例如,对于前面的数字,描述(用于培训)是:"The cat standing on the table is next to a couple of cups"。上一个例子的过程如下图所示。
对于类似的问题,我查找了GCN-LSTM的实现示例(特别是在StellarGraph文档中),但没有发现任何问题。所以,我想知道,是否有办法使用StellarGraph构建这样一个模型?如果是,怎么做?否则,哪个工具可以帮助我建立这个模型?
回答 1
Stack Overflow用户
发布于 2020-07-21 04:55:26
GCN用于编码具有序列节点特征的图形,并对这些序列进行预测。在这种情况下,您可能会尝试对一个具有固定功能的图形进行编码,然后使用该编码来生成一个句子。
为此,一个合适的模型是使用一个图形分类模型,例如GCNSupervisedGraphClassification或DeepGraphCNN。这些可用于将图形编码到向量以输入到单独的LSTM解码器中。
值得注意的是,这些模型不能很容易地集成边缘特性/类型,因此必须调整on/next to/standing建模的某些方面;例如将其作为特性合并到节点中。
例如,可以用更复杂的解码器模型(即Dense(units=1, activation="sigmoid") )替换https://stellargraph.readthedocs.io/en/stable/demos/graph-classification/gcn-supervised-graph-classification.html#Create-the-Keras-graph-classification-model中的最终https://stellargraph.readthedocs.io/en/stable/demos/graph-classification/gcn-supervised-graph-classification.html#Create-the-Keras-graph-classification-model层(或更多的https://stellargraph.readthedocs.io/en/stable/demos/graph-classification/gcn-supervised-graph-classification.html#Create-the-Keras-graph-classification-model层)。
(这个答案是从我对一个非常相似(相同?)的答复中复制出来的。在StellarGraph社区论坛上提出的问题:原创,归档。)
https://stackoverflow.com/questions/62886092
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号