
陷入了困境,陷入困境
陷入了困境,陷入困境
提问于 2020-07-13 08:54:49
我试图在一个引用全世界经济学家的站点中刮、HTML或JSON文件。下面是我试图利用的页面的一个例子:https://ideas.repec.org/f/pan296.html
更准确地说,我正在尝试刮,单击按钮“Export”、JSON、HTML或其他任何内容时显示的数据。以下是我所做的:
test <- rvest::html_session("https://ideas.repec.org/f/pan296.html") %>% jump_to("https://ideas.repec.org/cgi-bin/refs.cgi")
test$response连接很好,但是输出是空的:
Response [https://ideas.repec.org/cgi-bin/refs.cgi]
Date: 2020-07-13 08:50
Status: 200
Content-Type: text/plain; charset=utf-8
<EMPTY BODY>知道吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-07-13 10:25:04
正如阿齐兹所说,你必须观察POST请求才能重建它。但是在这种情况下,工作可能很棘手,因为新选项卡中的请求。按照以下主题查看如何观察新选项卡中打开的请求:Chrome Dev Tools: How to trace network for a link that opens a new tab?
获取导出内容的代码:
library(rvest)
url <- "https://ideas.repec.org/f/pan296.html"
pg <- html_session(url)
handle_value <- pg %>% html_node(xpath = "//form/input[@name='handle']") %>% html_attr("value")
pg <- pg %>% rvest:::request_POST(url = "https://ideas.repec.org/cgi-bin/refs.cgi",
body = list("handle"= handle_value,
"ref" = "Export references ",
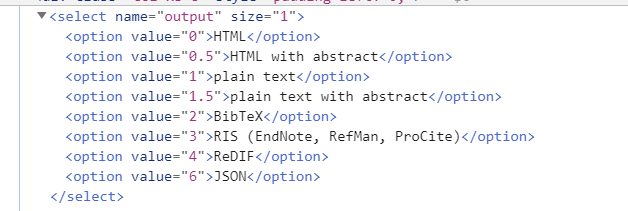
"output" = "0"))
pg$response(更改output数字值以获得不同的输出格式,0用于HTML)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62872451
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号