
差分隐私显着降低了模型性能
背景信息
我训练了一个分类器来预测三个标签:基于胸部X线图像的COVID/肺炎/健康。它是PyTorch实现的COVID-网络。我使用一个训练集来训练,使用验证集来保存性能最好的模型,然后使用一个测试集来衡量模型的“真实”性能。然而,我注意到我的模型“学会了”对正常/肺炎进行分类非常好,但它忽略了人口不足的COVID集。因此,我选择样本不足(减少其他课程(正常和肺炎)的培训实例数量,以获得平等的群体)。这是很好的工作,但我的样本集已经减少到1500个样本(低!)结果比COVID差一些,我对人口不足的类(COVID)获得了80%的精度和较低的敏感性。我认为它们报告了更好的性能,因为它们不使用验证集,并且使用每个时代的测试集。我想他们可能因为这个而间接地适应了测试集。我选择解释这一点,这样读者就能得到一个上下文。
问题
我尝试通过使用差异隐私来增加培训过程中的隐私。具体来说,我使用了Facebook的PyTorch-DP模块。如果我选择增加几乎没有隐私(这可以通过选择一个非常低的噪声乘数值(sigma),即1e-7)和一个非常高的增量来实现,那么培训也同样有效。所以,这并不是说模块本身没有工作/故障,而是,如果我使用更低的西格玛(所以我添加了更多的噪音),那么我得到了更多的隐私(epsilon减少了),但是模型根本不适合数据。的问题是:如何在一定程度上增加隐私,同时确保我的模型仍然适合数据?
性能差异
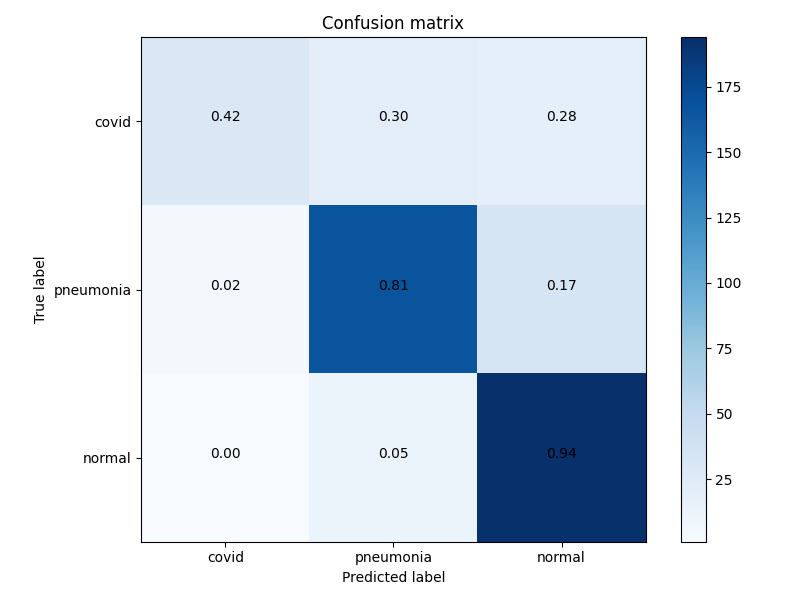
不加差别隐私的模型混淆矩阵。这不是“好”,但至少有点意义,该模型的准确率达到了80%。
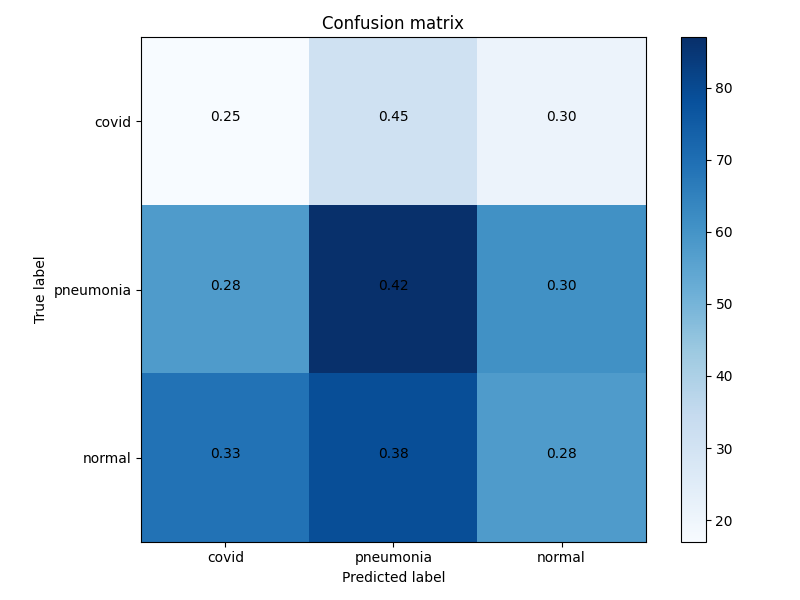
差异隐私模型的混淆矩阵(epsilon: 2.3)看起来,这个模型根本不知道该做什么。
可能的解释
我读到了一个纸,它指出添加差异隐私会导致糟糕的性能,因为对于人口不足的类,准确性会降低。但是,我使用了欠采样,我认为这应该解决这个问题,但准确性仍然很差(对所有的类!)
也许是因为我的样本集太小,差异隐私很难实现,因此性能不好吗?然而,即使增加了一点隐私,并且epsilon值>20000,该模型在学习如何分类方面仍然困难重重。所以我不确定。
回答 1
Stack Overflow用户
发布于 2020-06-14 19:11:51
似乎来自Facebook研究的PyTorch差异隐私库是建立在仁义差异隐私保障概念的基础上的,它非常适合于表达隐私保护算法的保证和异构机制的组合。我们需要对这个COVID-网络数据集的异质性进行一个很好的估计.
特别是Rényi散度满足数据处理不等式。目前的库似乎更适合于数据集中异构性较强的机器学习问题。该库使用差分私有随机梯度下降(SGD)算法的一个实现。它遵循随机初始化、梯度计算、裁剪梯度、加噪声和下降的顺序。裁剪和噪声参数可能随训练步骤和时间的不同而变化。
差异隐私在深度学习问题上的成功取决于预处理的程度、保护隐私的梯度和privacy_accounting,后者跟踪了培训过程中的隐私开销。指出在差分私有深度学习中,模型精度对训练参数(如批量大小和噪声水平)比对神经网络的结构更敏感。
在PyTorch库中,我们可以看到ImageNet、MNIST、DCGAN等方面的例子。在所有这些例子中,我们可以看到如何改变这些参数,如裁剪、批大小等,以获得所需的精度水平。请参阅PyTorch DP库中的以下示例脚本。
https://stackoverflow.com/questions/62246851
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号