
浏览器请求和curl请求之间有什么区别?
https://psycnet.apa.org/record/2016-47119-002
当我通过chrome (在私有窗口中)访问上面的URL时,我可以看到第一个请求,它对应于下面的curl命令。但是,当我在命令行中调用这个curl命令时,将通过显示<div id="distilIdentificationBlock"> </div>的蒸馏网络来检测它。
这在我看来很奇怪,因为这是第一个请求。除非curl发送的请求和chrome发送的请求有区别,否则蒸馏网络无法判断是由bot还是通过真正的浏览器发送什么请求。有人知道curl请求和chrome请求之间有什么不同吗?
curl 'https://psycnet.apa.org/record/2016-47119-002' \
-H 'Connection: keep-alive' \
-H 'Pragma: no-cache' \
-H 'Cache-Control: no-cache' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \
-H 'Sec-Fetch-Site: none' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-User: ?1' \
-H 'Sec-Fetch-Dest: document' \
-H 'Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7' \
--compressed如果我使用firefox提取相应的curl命令,问题也是一样的。因此firefox请求和curl请求之间的区别也是相关的。
回答 1
Stack Overflow用户
发布于 2020-05-29 11:22:40
没有什么不同。
要了解“提取”(他们的web抓取保护系统)是如何工作的,您需要查看初始响应HTML:
当我在Chrome中请求并查看Dev工具中的初始响应(确保选中了“保存日志”)时,我发现响应实际上是一个简短的网页,其中包含一个嵌入式<script>,执行一些简单的“这个用户代理是一个web浏览器吗?”检查,就像运行脚本,寻找在web浏览器之外不存在的JavaScript DOM对象(假设HTTP完全能够运行脚本--顺便说一句,cURL和wget并不能运行脚本)。
如果脚本认为您的用户代理是一个web浏览器,那么它会使用一个动态生成的密码来执行另一个对真实内容的请求(我没有看这个密码的详细信息)--这就是为什么您不能使用cURL或wget重新请求真实内容的原因,因为每个请求的密码都是唯一的。
下面是初始页面响应中<script>元素的屏幕截图,并注意到页面的HTML中缺少实际内容。
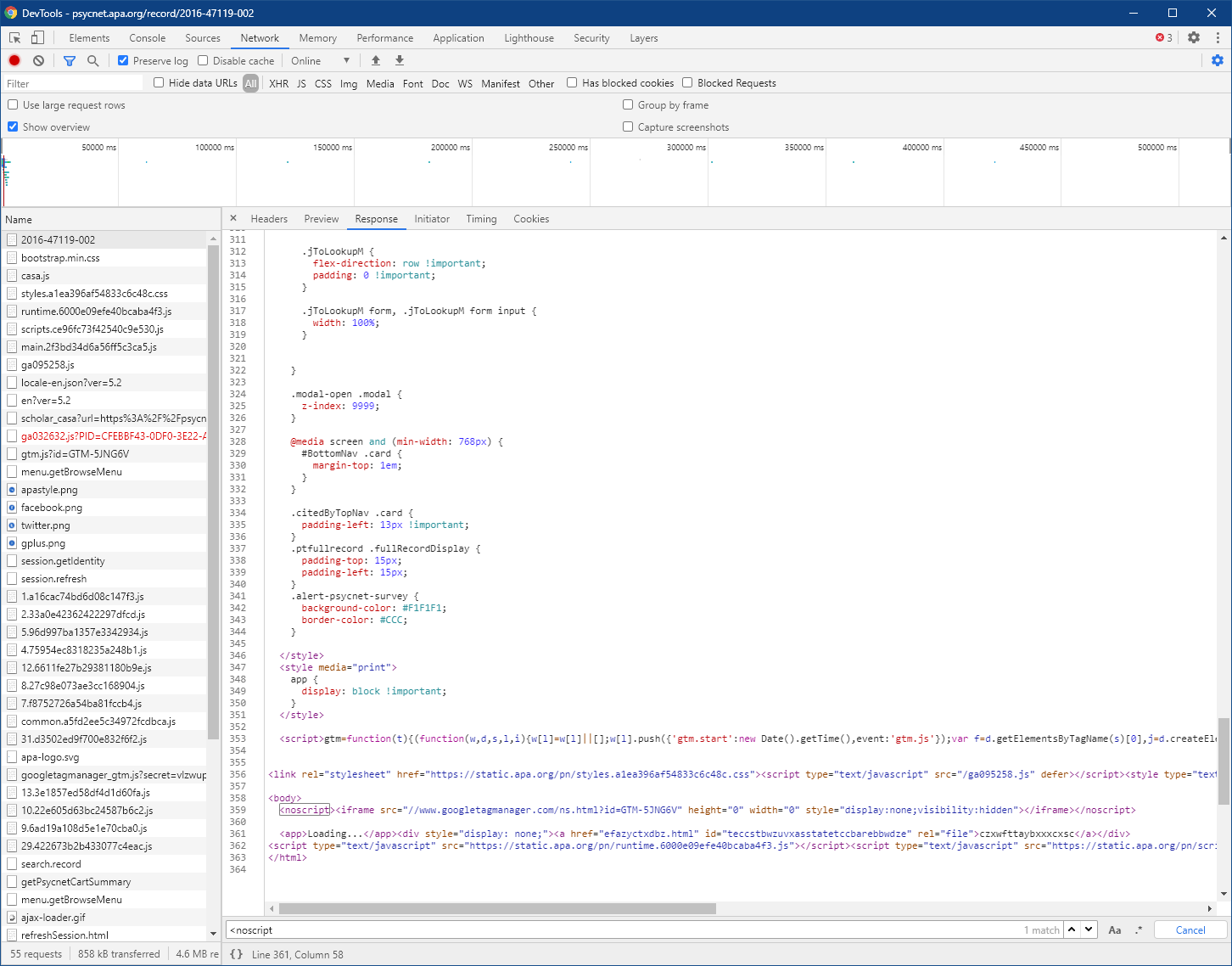
如果在浏览器中禁用JavaScript,则根本无法访问该网页。
这种防刮系统保护网页免受缺乏评估JavaScript的用户代理的请求,因此它将阻止curl、wget、HttpClient和浏览器内fetch/XMLHttpRequests (至少没有进一步的工作)。
你可能会认为这个系统会让搜索引擎蜘蛛无法索引网站,但这是一种古老的(根深蒂固的)信念和做法:因为直到2000年代末,主要的搜索引擎蜘蛛(谷歌、必应/Windows搜索、雅虎等)只对原始HTML进行索引,不运行JavaScript --但从那时起,搜索引擎蜘蛛开始运行JavaScript,甚至开始索引那些不使用自定义蜘蛛HTML解析器引擎的网站,而是使用实际的网页浏览器引擎(Google真正启动了它,这样它们就可以用角形、Vue等索引脚本重的网站,特别是单页应用程序)。当我在微软工作时,我开始在一些产品研究项目中使用必应爬虫系统,并使用专门构建的Internet来“运行”它访问过的网页。
https://stackoverflow.com/questions/62074890
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号