
最长公共子序列直觉
LCS代码的递归版本如下(m,n分别是字符串X和Y的长度)
int lcs( char[] X, char[] Y, int m, int n ) {
if (m == 0 || n == 0)
return 0;
if (X[m-1] == Y[n-1])
return 1 + lcs(X, Y, m-1, n-1);
else
return max(lcs(X, Y, m, n-1), lcs(X, Y, m-1, n));
} 我注意到,这个algo从末尾删除字符串的字符,并创建原始两个字符串的各种子字符串,然后尝试查找匹配的字符串。
我不明白的是,既然它只考虑某些子串,而不是所有可能的子序列,那么如何保证该算法能够提供正确的结果?这背后有逻辑/数学/直觉的证据吗?
回答 2
Stack Overflow用户
发布于 2020-05-14 09:27:21
当最后一个字符相同时,它计算lcs( X,Y,m-1,n-1)。
或
当字符不同时,计算lcs( X,Y,m-1,n)和lcs( X,Y,m,n-1)。
因此,它涵盖了所有可能的解决方案。
如果长度是0。那么lcs是0。如果最后(或第一)项相同,那么lcs是1+ lcs(X,Y,m-1,n-1) --这个子句通过向lcs添加公共元素来减少问题,并找到两个较短字符串的较小lcs。
最后最长的子序列是
lcs(X,Y,m-1,n)
或
lcs(X,Y,m,n-1)
因此,当它被要求计算lcs时( "abce","bghci",4,5);
if( m(4) == 0 || n(5) == 0 ) // evaluates to false
if( X[3]('e') == Y[4] ) // evaluates to false
return max( lcs( "abc", "bghci", 3, 5 ), // These two recursive calls
lcs( "abce", "bghc", 4, 4 ) ); // cover the whole problem space例如:
(A) lcs( "abce", "bghci" ) => (B) lcs( "abc", "bghci" )
(C) lcs( "abce", "bghc" )
(B) lcs( "abc", "bghci" ) => (D) lcs( "ab", "bghci" )
(E) lcs( "abc", "bghc" )
(C) lcs( "abce", "bghc" ) => (F) lcs( "abc", "bghc" )
(G) lcs( "abce", "bgh" )
(D) lcs( "ab" , "bghci") => (H) lcs( "a" , "bghci")
(I) lcs( "ab" , "bghc" )
(E) lcs( "abc", "bghc" ) => 1 + (J) lcs( "ab" , "bgh")
(F) lcs( "abc", "bghc" ) => 1 + (K) lcs( "ab" , "bgh")
(G) lcs( "abce", "bgh" ) => (L) lcs( "abc", "bgh" )
(M) lcs( "abce", "bg" )
(H) lcs( "a", "bghci") => lcs( "", "bghci" ) (0)
(N) lcs( "a", "bghc" )
(I) lcs( "ab", "bghc") => (O) lcs( "a", "bghc" )
(P) lcs( "ab", "bgh" )
(J) lcs( "ab", "bgh" ) => (Q) lcs( "a", "bgh" )
(R) lcs( "ab", "bg" )
(K) lcs( "ab", "bgh" ) => (S) lcs( "a", "bgh" )
(T) lcs( "ab", "bg" )
(L) lcs( "abc", "bgh" ) => (U) lcs( "ab", "bg" )
(V) lcs( "abc", "bg" )
(M) lcs( "abce", "bg" ) => (W) lcs( "abc", "bg" )
(X) lcs( "abce","b" )
(N) lcs( "a", "bghc") => lcs( "", "bghc" ) (0)
(Y) lcs( "a", "bgh" )
(O) lcs( "a", "bghc" ) => lcs( "", "bghc" ) (0)
lcs( "a" "bgh" )
(P) lcs( "ab", "bgh" ) => (Z) lcs( "a", "bgh" )
(AA) lcs( "ab", "bg" )
(Q) lcs( "a", "bgh" ) => lcs( "", "bgh") (0)
(AB) lcs( "a", "bg")
(R) lcs( "ab", "bg" ) => (AC) lcs( "a", "bg")
(AD) lcs( "ab", "b" )
(S) lcs( "a", "bgh" ) => lcs( "", "bgh") (0)
(AE) lcs( "a", "bg" )
(T) lcs( "ab", "bg" ) => (AF) lcs( "a", "bg" )
(AG) lcs( "ab", "b" )
(U) lcs( "ab", "bg" ) => (AH) lcs( "a", "bg" )
(AI) lcs( "ab", "b" )
(V) lcs( "abc","bg" ) => (AJ) lcs( "ab", "bg" )
=> (AK) lcs( "abc", "b" )
(W) lcs( "abc","bg" ) => (AL) lcs( "ab", "bg" )
(AM) lcs( "abc", "b" )
(X) lcs( "abce", "b") => (AN) lcs( "abc", "b" )
lcs( "abce", "" ) (0)
(Y) lcs( "abce", "b") => (AO) lcs( "abc", "b" )
lcs( "abce", "" ) (0)
(Z) lcs( "a", "bgh") => lcs( "", "bgh" ) (0)
(AP) lcs( "a", "bg" )
(AA)lcs( "ab", "bg") => (AQ) lcs( "a", "bg" )
(AR) lcs( "ab", "b" )
(AB)lcs( "a", "bg") => lcs( "", "bg" ) (0)
(AS) lcs( "a", "b" )
(AC)lcs( "a", "bg") => lcs( "", "bg") (0)
(AT) lcs( "a", "b")
(AD)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(AE)lcs( "a", "bg") => lcs( "", "bg")
(AU) lcs( "a", "b" )
(AF)lcs( "a", "bg") => lcs( "", "bg") (0)
(AV) lcs( "a", "b")
(AG)lcs( "ab", "b" ) => 1 + lcs( "a", "" ) (1)
(AH)lcs( "a", "bg") => lcs( "", "bg") (0)
(AW) lcs( "a", "b" )
(AI)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(AJ)lcs( "ab", "bg") => (AX) lcs( "a", "bg")
(AK)lcs( "abc", "b") => (AY) lcs( "ab", "b")
lcs( "abc", "b") (0)
(AL)lcs( "ab", "bg") => (AZ) lcs( "a", "bg")
(BA) lcs( "ab", "b")
(AM)lcs( "abc", "b") => (BB) lcs( "ab", "b")
lcs( "abc", "" ) (0)
(AN)lcs( "abc", "b") => (BC) lcs( "ab", "b")
lcs( "abc", "" ) (0)
(AO)lcs( "abc", "b") => (BD) lcs( "ab", "b")
lcs( "abc", "" ) (0)
(AP)lcs( "a", "bg") => lcs( "", "bg") (0)
(BE) lcs( "a", "b")
(AQ)lcs( "a", "bg") => lcs( "", "bg") (0)
(BF) lcs( "a", "b")
(AR)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(AS)lcs( "a", "b") => lcs( "", "b") (0)
lcs( "a", "" ) (0)
(AT)lcs( "a", "b" ) as (AS)
(AU)lcs( "a", "b" ) as (AS)
(AV)lcs( "a", "b") as (AS)
(AW)lcs( "a", "b") as (AS)
(AX)lcs( "a", "bg") => lcs( "", "bg") (0)
(BG) lcs( "a", "b")
(AY)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(AZ)lcs( "a", "bg") => lcs( "", "bg") (0)
(BH) lcs( "a", "b")
(BA)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(BB)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(BC)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(BD)lcs( "ab", "b") => 1 + lcs( "a", "" ) (1)
(BE)lcs( "a", "b") as (AS)
(BF)lcs( "a", "b") as (AS)
(BG)lcs( "a", "b") as (AS)因此,2的lcs来自以下调用堆栈.
lcs( "abcde", "bghci") // (A)
lcs( "abcd", "bghci" ) // (B)
lcs( "abc", "bghc" ) // (E)
1 + lcs( "ab", "bgh" ) // (J)
lcs( "ab", "bg" ) // (R)
lcs( "ab", "b" ) // (AD)
1 + lcs( "a", "" ) 正如你所看到的,它测试了更多的组合。
我不明白的是,因为它只考虑某些子字符串,而不是所有可能的子序列,
该算法的诀窍是,如果第一个字符(或最后一个字符相同),那么最长的公共子序列是1+两个较短字符串的lcs。通过归纳或矛盾来证明,可以帮助你证明分工是必要的,足以涵盖所有可能的选择。
从我的构建中可以看出,它在计算lcs时考虑了很多选择,所以它不是一个非常有效的算法。
Stack Overflow用户
发布于 2020-05-14 16:48:36
动态编程的一个步骤是猜测(查看麻省理工学院关于YouTube的讲座)。
两个字符串中的每个字符都有两个指针。
这里的猜测要么包含该字符,要么不包含该字符。
如果两个字符都相同,则包含该字符并将指针向前移动。max(lcs(X, Y, m, n-1), lcs(X, Y, m-1, n))
- 从字符串X或Y中选择了一个字符。
它的重复如下:
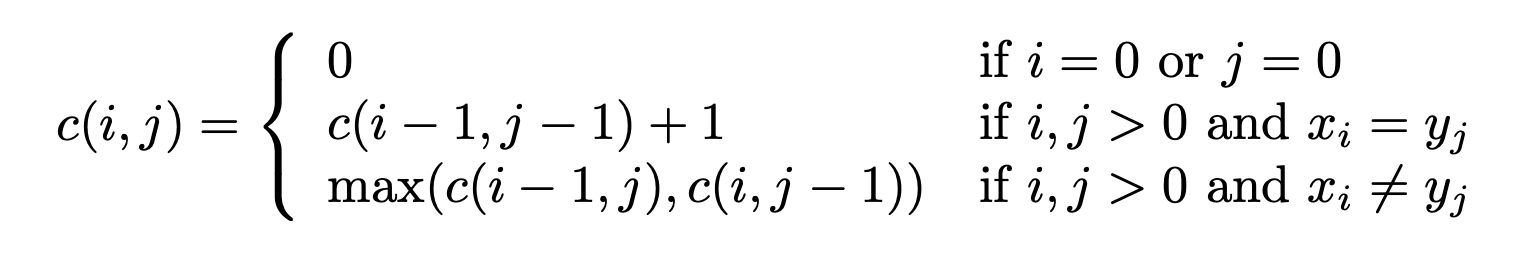
由于你在猜测所有可能的结果,上面的重复给出了正确的答案。
如需更多参考:https://courses.csail.mit.edu/6.006/fall10/handouts/recitation11-19.pdf
https://stackoverflow.com/questions/61791830
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号