
在语言建模中,变压器是否需要位置编码?
我正在开发一个像tutorial.html这样的语言模型。
对我来说还不清楚--这里是否需要位置编码?据我所知,语言翻译任务是必要的,因为解码器应该能够在编码器的序列中定位来自先前输出的单词。但是,在没有解码器的语言建模中,这是否有必要呢?
编码器输出中的单词有可能被洗牌吗?
编辑:
原文中没有任何解释。我在教程中没有找到解释(比如这里的编码/编码)。
我不明白这一点:
“当一个句子中的每个单词同时通过转换器的编解码堆栈时,模型本身对每个单词没有任何位置/顺序感。”
在我看来-转换器编码器有关于顺序的信息,因为它的输入是一个有序的序列(类似于RNN)。
我试图从模型中删除位置编码。效果很好,但表现更差。
在RNN中添加这样的位置编码有用吗?它能改善它的性能吗?
回答 3
Stack Overflow用户
发布于 2020-09-18 02:01:44
这个研究小组声称位置编码是不必要的:https://arxiv.org/abs/1905.04226。
Stack Overflow用户
发布于 2021-11-04 20:47:15
我看到了下面的视频,https://www.youtube.com/watch?v=S27pHKBEp30,他在16:00左右的时间戳上说,如果没有位置编码,注意力机制只是一个‘单词袋’。
Stack Overflow用户
发布于 2022-04-10 03:25:27
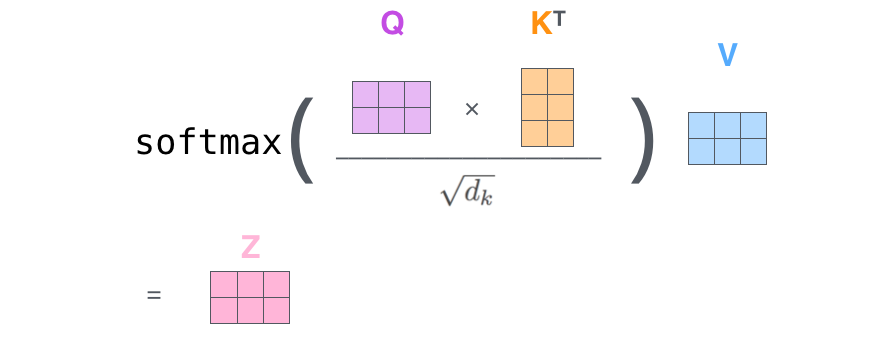
取自https://jalammar.github.io/illustrated-transformer/
改变单词的顺序,将改变V行的顺序,但也会改变相关矩阵Q x transpose(K)的列的顺序。因此,结果输出将保持不变,位置信息将在第一自我注意层之后丢失。
为了解决这个问题,你可以将位置编码到每个单词的嵌入中,这样神经网络就可以学会接受两个嵌入,并且知道它们无论输入的顺序有多远。
从声明位置编码是不必要的的摘要中
位置编码是对序列顺序不变的自我注意机制的一种必要的增强。
https://stackoverflow.com/questions/61440281
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号