
RNN/LSTM信元的解释
目前我正在学习RNN,特别是LSTM网络。我读过很多主题,包括这一个和我仍然有一些误解。下面的图像来自这篇文章,它表示单个RNN单元在时间上展开。
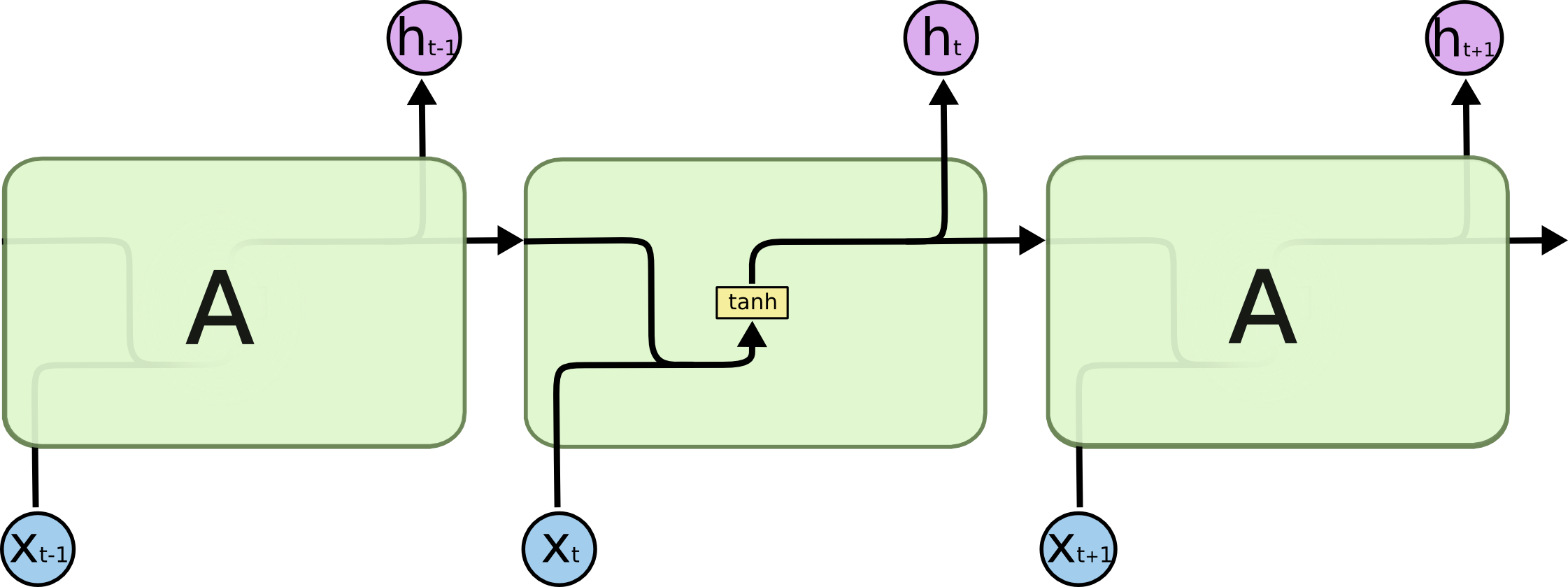
1.我是否正确理解,从前馈神经网络的角度来说,RNN细胞不是单个神经元,而是其内部的一层神经元?
文章中的另一张图像代表了在时间上展开的单个LSTM单元。
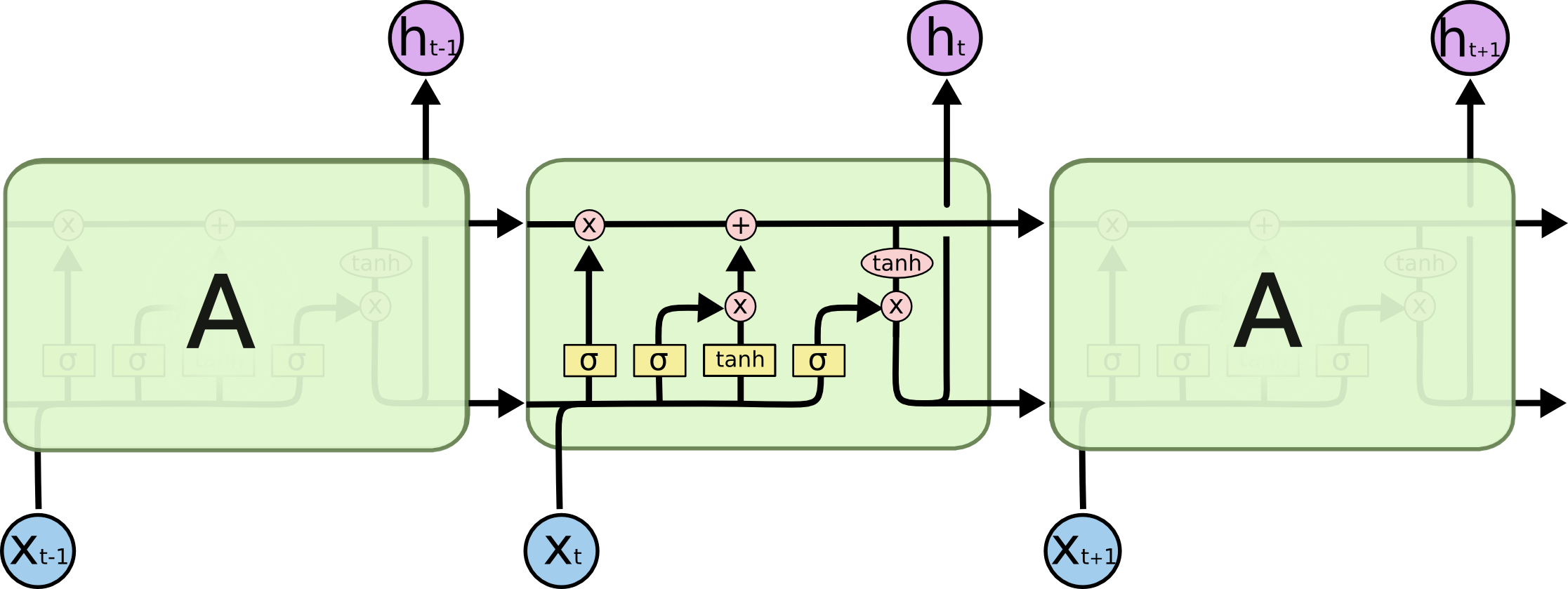
2.基于第一个问题的逻辑,从前馈神经网络的角度看,LSTM细胞不是一个单一的神经元,而是一组4层的神经元,在它的内部?。
3.粗略地说,我们可以说,RNN (或LSTM)层(例如Keras层)是我们所称的“cell”?。
提前感谢您的回答!
回答 1
Stack Overflow用户
发布于 2020-04-26 04:24:44
考虑到您发布的图表,如您所见,每个单元使用其前体单元的输出。例如,当您想要将x2中的内容输入到您的LSTM网络时,您必须使用来自前一个单元格的h1 (即前一个时间步骤的输出)以及x2的向量。给这两个单元喂食会给您h2,然后它将被前向传播到下一个单元。这是timestep t=2中发生的事情的一个例子。
递归神经网络可以被认为是同一网络的多个副本,每个副本传递一个消息给后继人。但是,在教程中,您可以看到这些网络是为了便于理解而展开的。这并不是在实践中所发生的事情,因为所描绘的细胞并不是分开的,因为它们都有相同的参数,这些参数都会在每次反向传播迭代中得到更新。
为了让它更容易理解,请考虑下面的代码片段。
# X is the input sequence (e.g., word embeddings vectors)
# steps is the input sequence length
# h0, and c0 are zero state vector (commonly done) that you want to
# feed into the first RNN cell
# h_out is the hidden states that the RNN network outputs
X = torch.randn(seq_len, hidden_dim)
steps = range(seq_len)
h0 = torch.zeros(seq_len, hidden_dim)
c0 = torch.zeros(seq_len, hidden_dim)
hidden = (h0, c0)
h_out = list()
for i in steps:
# advance rnn
hidden = RNN(X[i], hidden)
hy, cy = hidden
h_out.append(hy)假设RNN(.,.)是一个RNN (LSTM/GRU)单元,它具有一系列可训练的参数,如权重矩阵和偏差。这些参数都是相同的,并由每个X[i]和hidden实例学习,这些实例在每次迭代时都被输入RNN单元。
所以回到你的问题上,RNN网络实际上是RNN单元的多个副本,当你进行训练时,它会被训练。
https://stackoverflow.com/questions/61399871
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号