
有可能微调伯特做转发预测吗?
我想构建一个分类器来预测用户i是否会转发tweet j。
这个数据集很大,包含了1.6亿条推特。每条推文都伴随着一些元数据(例如,转发者是否跟踪推特的用户)。
单个tweet的文本标记是BERT ids的有序列表。要获得tweet的嵌入,只需使用it (所以它不是文本)。
有可能微调伯特来做预测吗?如果是,您推荐哪些课程/来源来学习如何微调?(我是初学者)
我要补充的是,预测应该是一个概率。
如果不可能,我正在考虑将嵌入转换回文本,然后使用我将要训练的任意分类器。
回答 2
Stack Overflow用户
发布于 2020-04-24 23:35:28
你可以微调伯特,你可以使用伯特做转发预测,但你需要更多的架构来预测用户我是否会转发推特j。
这是我头顶上的建筑。
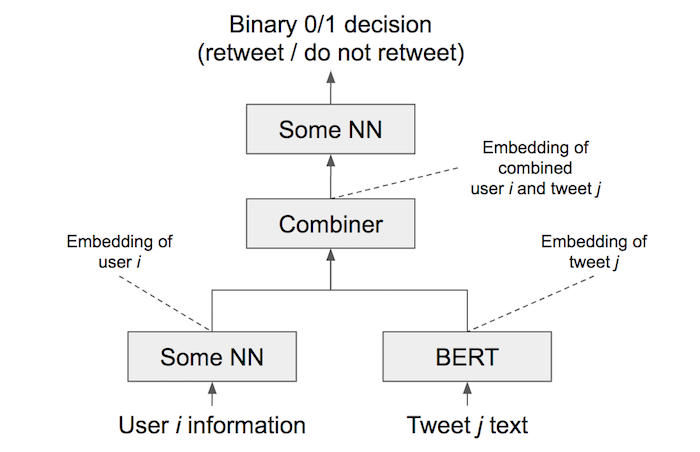
在高级别:
- 创建用户i的密集向量表示(嵌入)(可能包含与用户兴趣有关的内容,如体育)。
- 创建tweet j的嵌入。
- 创建前两个嵌入组合在一起的嵌入,例如级联或hadamard积。
- 通过执行二进制分类来预测转发集或非转发集的NN提供此嵌入信息。
让我们逐项分解这个体系结构。
要创建用户i的嵌入,您需要创建某种神经网络,它接受用户的任何特性并生成密集的向量。这部分是架构中最困难的部分。这个领域并不在我的掌控范围内,但是谷歌快速搜索“用户兴趣嵌入”会带来一篇关于StarSpace算法的研究论文。它建议它可以“根据用户行为获得信息丰富的用户嵌入”,这正是您所希望的。
要创建tweet的嵌入,您可以使用任何类型的神经网络来获取标记并生成向量。2018年之前的研究将建议使用LSTM或CNN来产生这种载体。然而,伯特(正如你在你的帖子中提到的)是目前最先进的。它接受文本(或文本索引)并为每个令牌生成一个向量;其中一个标记应该是前缀[CLS]令牌,通常被看作是整个句子的表示。这篇文章提供了对流程的概念概述。正是在架构的这一部分,你可以微调伯特。本网页提供了具体的代码,使用PyTorch和BERT的Huggingface实现来完成这个步骤(我已经完成了这些步骤,并且可以为它提供担保)。在未来,你会想谷歌“伯特单句分类”。
要创建一个表示用户i和tweet组合的嵌入,您可以做许多事情之一。您可以简单地将它们连接到一个向量中;因此,如果用户i是一个M维向量,而tweet是一个N维向量,那么级联就会生成一个(M+N)-dimensional向量。另一种方法是计算hadamard乘积(按元素进行乘法);在这种情况下,两个向量必须具有相同的维数。
若要对转发集进行最终的分类,请构建一个简单的神经网络,该神经网络以组合向量为基础,并生成单个值。在这里,由于您正在进行二进制分类,带有逻辑(sigmoid)函数的NN将是合适的。您可以将输出解释为重发的概率,因此超过0.5的值将被转发。有关为二进制分类构建NN的基本细节,请参见本网页。
为了让整个系统正常工作,你需要把它和端到端一起训练。也就是说,你必须先把所有的部件连接起来,然后训练它,而不是单独训练组件。
您的输入数据集将如下所示:
user tweet retweet?
---- ----- --------
20 years old, likes sports Great game Y
30 years old, photographer Teen movie was good N 如果您希望在没有用户个性化设置的情况下找到更简单的路径,那么只需删除创建用户i嵌入的组件即可。您可以使用BERT构建一个模型,以确定tweet是否被转发而不考虑用户。您可以再次遵循我上面提到的链接。
https://stackoverflow.com/questions/61350737
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号