
用TensorFlow为多目标跟踪中的每个目标创建多个权值张量
用TensorFlow为多目标跟踪中的每个目标创建多个权值张量
提问于 2020-04-13 14:44:34
我正在使用TensorFlow V1.10.0并开发一个基于MDNet的多目标跟踪器.我需要为每个检测到的对象为完全连接的层分配一个单独的权重矩阵,以便在在线培训期间为每个对象获得不同的嵌入。我使用这个tf.map_fn来生成一个高阶权张量(n_objects,平坦层,hidden_units),
“”“
def dense_fc4(n_objects):
initializer = lambda: tf.contrib.layers.xavier_initializer()(shape=(1024, 512))
return tf.Variable(initial_value=initializer, name='fc4/kernel',
shape=(n_objects.shape[0], 1024, 512))
W4 = tf.map_fn(dense_fc4, samples_flat)
b4 = tf.get_variable('fc4/bias', shape=512, initializer=tf.zeros_initializer())
fc4 = tf.add(tf.matmul(samples_flat, W4), b4)
fc4 = tf.nn.relu(fc4)“”“
然而,在执行过程中,当我为W4运行会话时,我会得到一个权重矩阵,但所有这些都具有相同的值。有什么帮助吗?
提亚
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-05-05 03:52:13
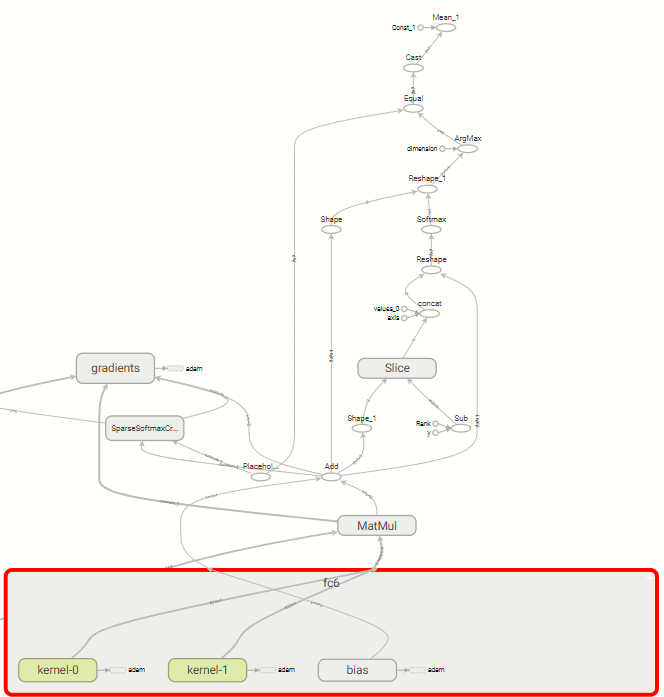
下面是一个解决办法,我能够在for循环中生成图形外部的多个内核,然后将其交给图形:
w6 = []
for n_obj in range(pos_data.shape[0]):
w6.append(tf.get_variable("fc6/kernel-" + str(n_obj), shape=(512, 2),
initializer=tf.contrib.layers.xavier_initializer()))
print("modeling fc6 branches...")
prob, train_op, accuracy, loss, pred, initialize_vars, y, fc6 = build_branches(fc5, w6)
def build_branches(fc5, w6):
y = tf.placeholder(tf.int64, [None, None])
b6 = tf.get_variable('fc6/bias', shape=2, initializer=tf.zeros_initializer())
fc6 = tf.add(tf.matmul(fc5, w6), b6)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,
logits=fc6))
train_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="fc6")
with tf.variable_scope("", reuse=tf.AUTO_REUSE):
optimizer = tf.train.AdamOptimizer(learning_rate=0.001, name='adam')
train_op = optimizer.minimize(loss, var_list=train_vars)
initialize_vars = train_vars
initialize_vars += [optimizer.get_slot(var, name)
for name in optimizer.get_slot_names()
for var in train_vars]
if isinstance(optimizer, tf.train.AdamOptimizer):
initialize_vars += optimizer._get_beta_accumulators()
prob = tf.nn.softmax(fc6)
pred = tf.argmax(prob, 2)
correct_pred = tf.equal(pred, y)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
return prob, train_op, accuracy, loss, pred, initialize_vars, y, fc6
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61190366
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号