
如何绘制KMeans?
如何绘制KMeans?
提问于 2020-04-12 20:03:28
我正在尝试使用MiniBatchKMeans和更大的数据集,并绘制2种不同的属性。我收到了一个Keyerror: 2,我相信我在for循环中出错了,但是我不知道在哪里。有人能帮我看出我的错误是什么吗?我正在运行以下代码:
import numpy as np ##Import necessary packages
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import *
from sklearn.cluster import MiniBatchKMeans
url2="http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" #Reading in Data from a freely and easily available source on the internet
Adult = pd.read_csv(url2, header=None, skipinitialspace=True) #Decoding data by removing extra spaces in cplumns with skipinitialspace=True
##Assigning reasonable column names to the dataframe
Adult.columns = ["age","workclass","fnlwgt","education","educationnum","maritalstatus","occupation",
"relationship","race","sex","capitalgain","capitalloss","hoursperweek","nativecountry",
"less50kmoreeq50kn"]
print("reviewing dataframe:")
print(Adult.head()) #Getting an overview of the data
print(Adult.shape)
print(Adult.dtypes)
np.median(Adult['fnlwgt']) #Calculating median for final weight column
TooLarge = Adult.loc[:,'fnlwgt'] > 748495 #Setting a value to replace outliers from final weight column with median
Adult.loc[TooLarge,'fnlwgt']=np.median(Adult['fnlwgt']) #replacing values from final weight Column with the median of the final weight column
Adult.loc[:,'fnlwgt']
X = pd.DataFrame()
X.loc[:,0] = Adult.loc[:,'age']
X.loc[:,1] = Adult.loc[:,'hoursperweek']
kmeans = MiniBatchKMeans(n_clusters = 2)
kmeans.fit(X)
centroids = kmeans.cluster_centers_
labels = kmeans.labels_
print(centroids)
print(labels)
colors = ["g.","r."]
for i in range(len(X)):
print("coordinate:",X[i], "label:", labels[i])
plt.plot(X.loc[:,0][i],X.loc[:,1][i], colors[labels[i]], markersize = 10)
plt.scatter(centroids[:, 0], centroids[:, 1], marker = "x", s=150, linewidths = 5, zorder = 10)
plt.show()当我运行for循环时,我只看到在散射矩阵中绘制的两个数据点。我是否需要与创建的数据框架不同地调用这些点?
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-04-12 20:46:34
您可以避免这个问题,不运行一个循环来分别绘制32,000个点中的每个点,这是错误的做法,也是不必要的。您可以简单地将两个数组传递给plt.scatter()来绘制这个散点图,不需要一个循环。使用以下几行:
colors = ["green","red"]
plt.scatter(X.iloc[:,0], X.iloc[:,1], c=np.array(colors)[labels],
s = 10, alpha=.1)
plt.scatter(centroids[:, 0], centroids[:, 1], marker = "x", s=150,
linewidths = 5, zorder = 10, c=['green', 'red'])
plt.show()
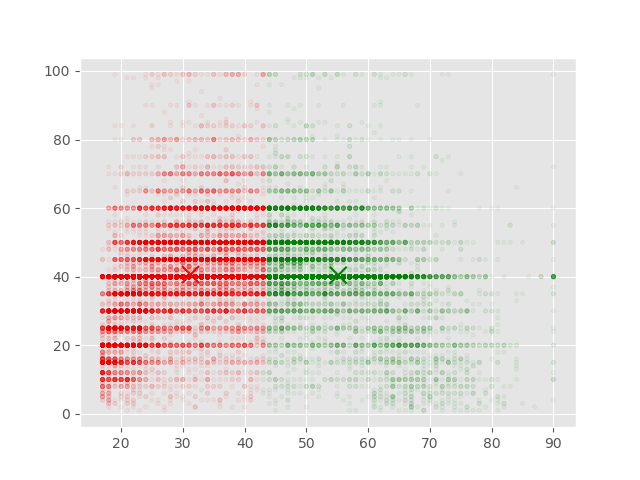
你最初的错误是由于对熊猫索引使用不当造成的。通过这样做,您可以复制错误:
df = pd.DataFrame(list('dasdasas'))
df[1]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61177418
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号