
什么是衡量训练成绩的好的学习率图?
我是培训从零,一个基于SSD的对象检测网络。我正在训练25万张图片。dataset对某些类具有倾斜性,但对于少数类(2000左右),我也有很好的表示。
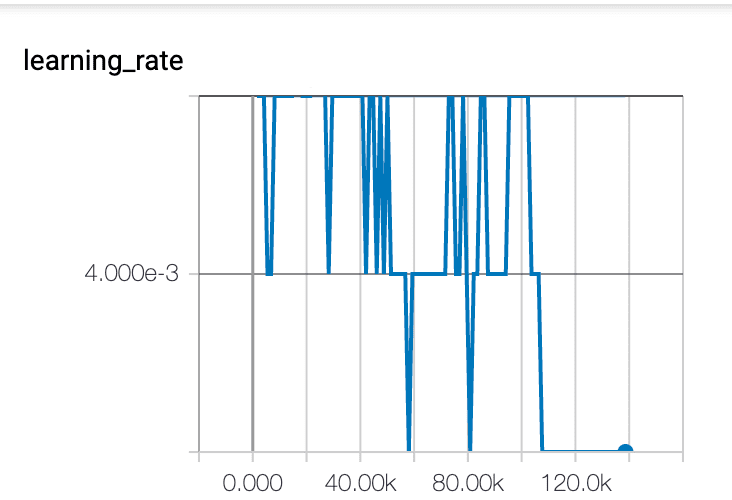
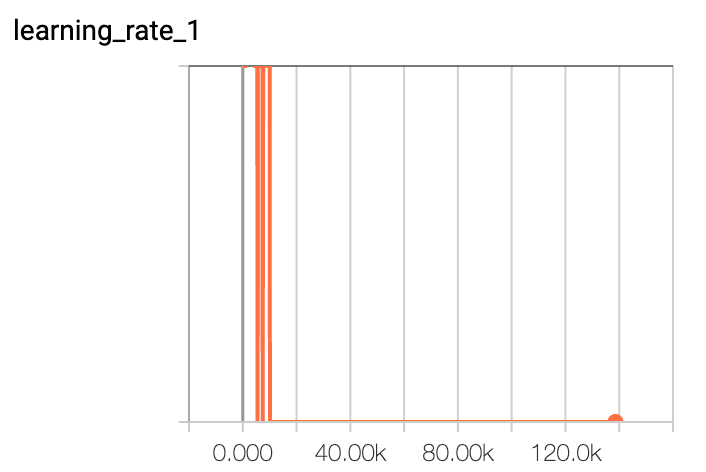
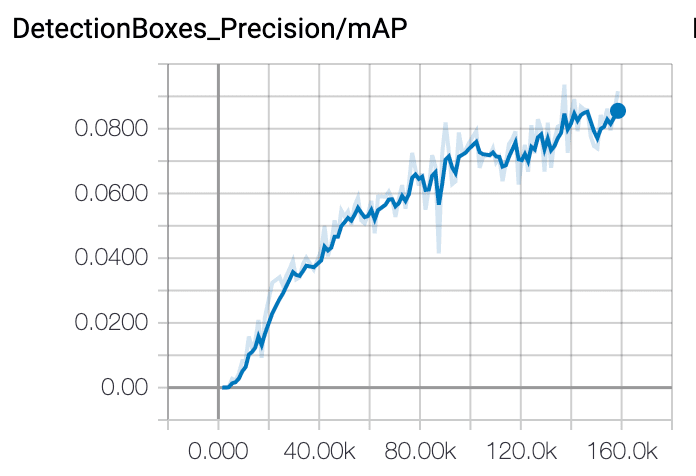
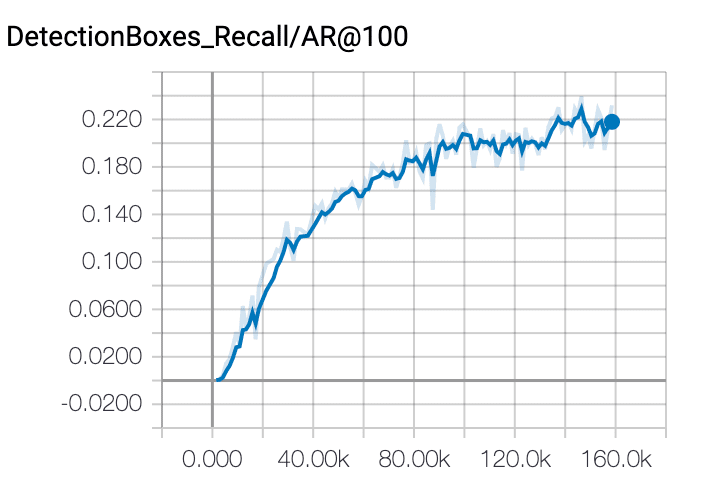
我发现该模型训练效果不佳,150 k步长,只有8%的准确率和25%的召回率。学习速度也不是一个平滑图。我应该期望什么样的学习速率图,以及我还能尝试哪些其他的事情来提高我的训练水平?
optimizer {
rms_prop_optimizer {
learning_rate {
exponential_decay_learning_rate {
initial_learning_rate: 0.004000000189989805
decay_steps: 800720
decay_factor: 0.949999988079071
}
}
momentum_optimizer_value: 0.8999999761581421
decay: 0.8999999761581421
epsilon: 1.0
}
}
回答 2
Stack Overflow用户
发布于 2020-04-08 05:58:09
你的模型的学习速度是poor.You,当然是过火了.
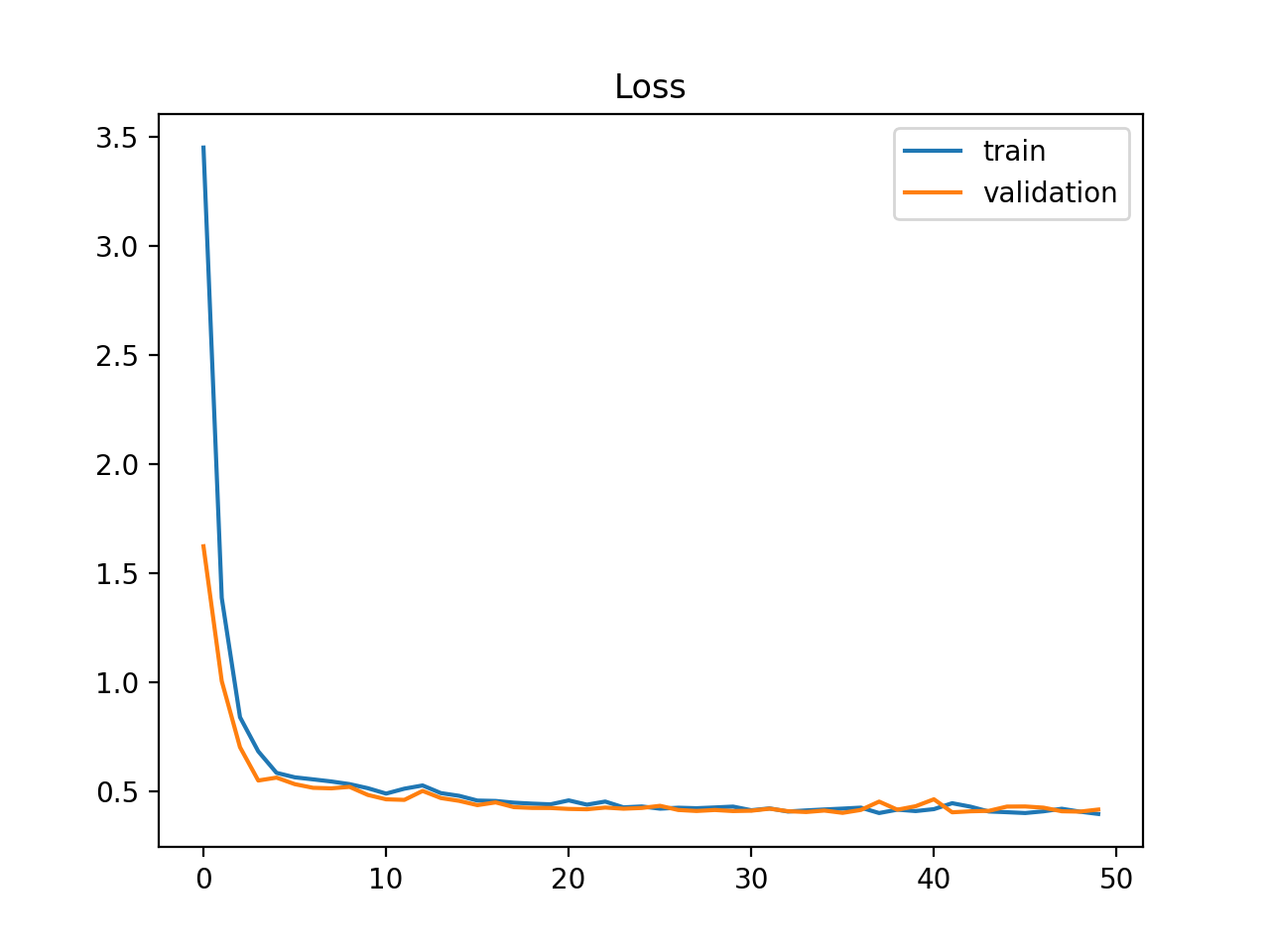
一些更改如下:1.首先进行交叉验证;2.尝试删除一些特性。3.确保标签正确编码。
可能有很多事情可能是错的。很难说。作为参考,我可以给你介绍一下建筑。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from layers import *
from data import voc, coco
import os
class SSD(nn.Module):
"""Single Shot Multibox Architecture
The network is composed of a base VGG network followed by the
added multibox conv layers. Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
Args:
phase: (string) Can be "test" or "train"
size: input image size
base: VGG16 layers for input, size of either 300 or 500
extras: extra layers that feed to multibox loc and conf layers
head: "multibox head" consists of loc and conf conv layers
"""
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = (coco, voc)[num_classes == 21]
self.priorbox = PriorBox(self.cfg)
self.priors = Variable(self.priorbox.forward(), volatile=True)
self.size = size
# SSD network
self.vgg = nn.ModuleList(base)
# Layer learns to scale the l2 normalized features from conv4_3
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
"""Applies network layers and ops on input image(s) x.
Args:
x: input image or batch of images. Shape: [batch,3,300,300].
Return:
Depending on phase:
test:
Variable(tensor) of output class label predictions,
confidence score, and corresponding location predictions for
each object detected. Shape: [batch,topk,7]
train:
list of concat outputs from:
1: confidence layers, Shape: [batch*num_priors,num_classes]
2: localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
"""
sources = list()
loc = list()
conf = list()
# apply vgg up to conv4_3 relu
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
def load_weights(self, base_file):
other, ext = os.path.splitext(base_file)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
self.load_state_dict(torch.load(base_file,
map_location=lambda storage, loc: storage))
print('Finished!')
else:
print('Sorry only .pth and .pkl files supported.')
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
def multibox(vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k]
* num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
mbox = {
'300': [4, 6, 6, 6, 4, 4], # number of boxes per feature map location
'512': [],
}
def build_ssd(phase, size=300, num_classes=21):
if phase != "test" and phase != "train":
print("ERROR: Phase: " + phase + " not recognized")
return
if size != 300:
print("ERROR: You specified size " + repr(size) + ". However, " +
"currently only SSD300 (size=300) is supported!")
return
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes)
return SSD(phase, size, base_, extras_, head_, num_classes)Stack Overflow用户
发布于 2020-04-20 13:40:03
这是一个超参数调优问题。
首先,你需要坚持一个基本的香草随机梯度下降,当你刚刚开始。这既是为了保持简单,也是为了了解您的数据集和模型。此外,这将降低您可以调优的超参数的数量。
然后,你应该训练一个低数量的时代(取决于培训时间),并以对数方式改变学习速度。
学习率:
0.0001
0.001
0.01
0.1
1.0
10
100
这样你就可以大致知道你的网络在哪里训练得很好。只有在找到一个不错的大致情况后,你才会开始增加指数衰减和动量。
尝试阅读超参数调谐上的一些资源。吴家辉的“课程”也是一种很好的构造和调整神经网络的教学方法。
回答你的问题:我认为你的学习率太低了。我希望学习率图的形状会有一点不同。但是,在动量与指数衰减相反的情况下,如果不明确地绘制它,就很难知道这一点。你的精确图和回忆图实际上表明网络正在学习一些东西。然而,由于你的学习速度下降,它看起来是非常低的峰值,然后变平。最有可能的是,你的学习率在这一点上实际上是零。
https://stackoverflow.com/questions/61091655
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号