
熊猫str.contains匹配不使用regex的精确子字符串
熊猫str.contains匹配不使用regex的精确子字符串
提问于 2020-04-07 09:59:34
我有两个dataframe,并试图找到一种方法来匹配从一个dataframe到另一个dataframe的精确子字符串。
First DataFrame
import pandas as pd
import numpy as np
random_data = {'Place Name':['TS~HOT_MD~h_PB~progra_VV~gogl', 'FM~uiosv_PB~emo_SZ~1x1_TG~bhv'],
'Site':['DV360', 'Adikteev']}
dataframe = pd.DataFrame(random_data)
print(dataframe)第二DataFrame
test_data = {'code name': ['PB', 'PB', 'PB'],
'Actual':['programmatic me', 'emoteev', 'programmatic-mechanics'],
'code':['progra', 'emo', 'prog']}
test_dataframe = pd.DataFrame(test_data)逼近
for k, l, m in zip(test_dataframe.iloc[:, 0], test_dataframe.iloc[:, 1], test_dataframe.iloc[:, 2]):
dataframe['Site'] = np.select([dataframe['Place Name'].str.contains(r'\b{}~{}\b'.format(k, m), regex=False)], [l],
default=dataframe['Site'])当前的输出如下所示,尽管我期望匹配精确的子字符串,该子字符串与上面的代码不兼容。
当前产出:
Place Name Site
TS~HOT_MD~h_PB~progra_VV~gogl programmatic-mechanics
FM~uiosv_PB~emo_SZ~1x1_TG~bhv emoteev预期产出:
Place Name Site
TS~HOT_MD~h_PB~progra_VV~gogl programmatic me
FM~uiosv_PB~emo_SZ~1x1_TG~bhv emoteev回答 2
Stack Overflow用户
发布于 2020-04-07 11:31:52
数据
import pandas as pd
import numpy as np
random_data = {'Place Name':['TS~HOT_MD~h_PB~progra_VV~gogl',
'FM~uiosv_PB~emo_SZ~1x1_TG~bhv'], 'Site':['DV360', 'Adikteev']}
dataframe = pd.DataFrame(random_data)
test_data = {'code name': ['PB', 'PB', 'PB'], 'Actual':['programmatic me', 'emoteev', 'programmatic-mechanics'],
'code':['progra', 'emo', 'prog']}
test_dataframe = pd.DataFrame(test_data)将test_datframe code和Actual分别映射为key和value字典
keys=test_dataframe['code'].values.tolist()
dicto=dict(zip(test_dataframe.code, test_dataframe.Actual))
dicto加入由|分隔的键,以便搜索任一短语
k = '|'.join(r"{}".format(x) for x in dicto.keys())
k从数据帧中提取符合k中任何短语的字符串,并将它们映射到字典中。
dataframe['Site'] = dataframe['Place Name'].str.extract('('+ k + ')', expand=False).map(dicto)
dataframe输出
Stack Overflow用户
发布于 2020-04-07 10:52:46
这不是最优雅的解决方案,但这确实有效。
设置数据
import pandas as pd
import numpy as np
random_data = {'Place Name':['TS~HOT_MD~h_PB~progra_VV~gogl',
'FM~uiosv_PB~emo_SZ~1x1_TG~bhv'], 'Site':['DV360', 'Adikteev']}
dataframe = pd.DataFrame(random_data)
test_data = {'code name': ['PB', 'PB', 'PB'], 'Actual':['programmatic me', 'emoteev', 'programmatic-mechanics'],
'code':['progra', 'emo', 'prog']}
test_dataframe = pd.DataFrame(test_data)解决方案
使用要匹配的子字符串在test_dataframe中创建一个列:
test_dataframe['match_str'] = test_dataframe['code name'] + '~' + test_dataframe.code
print(test_dataframe) code name Actual code match_str
0 PB programmatic me progra PB~progra
1 PB emoteev emo PB~emo
2 PB programmatic-mechanics prog PB~prog定义一个应用于test_dataframe的函数
def match_string(row, dataframe):
ind = row.name
try:
if row[-1] in dataframe.loc[ind, 'Place Name']:
return row[1]
else:
return dataframe.loc[ind, 'Site']
except KeyError:
# More rows in test_dataframe than there are in dataframe
pass
# Apply match_string and assign back to dataframe
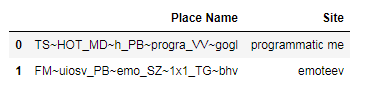
dataframe['Site'] = test_dataframe.apply(match_string, args=(dataframe,), axis=1)输出:
Place Name Site
0 TS~HOT_MD~h_PB~progra_VV~gogl programmatic me
1 FM~uiosv_PB~emo_SZ~1x1_TG~bhv emoteev页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61077406
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号