
OpenCV:消除Tesseract OCR的背景噪声
OpenCV:消除Tesseract OCR的背景噪声
提问于 2020-01-16 08:06:38
我有一个无人机FPV视频,我需要从中提取GPS坐标。文字是白色的,但由于视频质量差,它看起来是灰色和浅蓝色。由于背景的变化,我有一些问题,因为在一些帧中,背景有一个完全不同的,而在一些帧中,一个类似于文本的颜色。
以下是视频中的两幅原始图像(帧):
- 暗背景
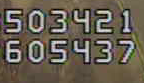
- 光本底

下面是我在googling之后找到的代码:
import numpy as np
import cv2
import pytesseract
cap = cv2.VideoCapture('v1.avi')
p = 10000
while(cap.isOpened()):
ret, frame = cap.read()
img = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
img = img[380:460, 220:640]
img = cv2.bilateralFilter(img, 9, 27, 27)
img = cv2.threshold(img, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
img = cv2.GaussianBlur(img, (9, 9), 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
img = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
img = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU)[1]
img = cv2.dilate(img, kernel)
img = cv2.threshold(img, 0, 250, cv2.THRESH_BINARY_INV)[1]
cv2.imshow('frame', img)
cv2.imshow('or', frame)
print('\n==============')
print(pytesseract.image_to_string(img, config='digits'))
if cv2.waitKey(50) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()并得出了以下结果:
- 暗背景
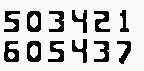
- 光本底

正如你所看到的,在第二种情况下,背景不清晰,有一些噪音,而从图像中Tesseract不能正确地提取文本。
编辑:出于某些原因,我不能分享我上面写的视频,但是以下是Youtube上的类似视频,如果可以从视频中提取文本,我猜这种方法也适用于我,或者至少可以解决许多问题:

回答 1
Stack Overflow用户
发布于 2020-01-16 11:25:10
我能够使用cv2.bilateralFilter和cv2.adaptiveThreshold的组合实现一些工作。一旦背景位于一个主块中,就可以根据它们的补丁大小提取数字。
img = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Bilaterial filter and adaptive histogram thresholding to get background into mostly one patch
img = cv2.bilateralFilter(img, 9, 29, 29)
thresh = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 13, 0)
# Add padding to join any background around edges into the same patch
pad = 2
img_pad = cv2.copyMakeBorder(thresh, pad, pad, pad, pad, cv2.BORDER_CONSTANT, value = 1)
# Label patches and remove padding
ret, markers = cv2.connectedComponents(img_pad)
markers = markers[pad:-pad,pad:-pad]
# Count pixels in each patch
counts = [(markers==i).sum() for i in range(markers.max()+1)]
# Keep patches based on pixel counts
maxCount = 200 # removes large background patches
minCount = 40 # removes specs and centres of numbering
keep = [c<maxCount and c>minCount for c in counts]
output = markers.copy()
for i,k in enumerate(keep):
output[markers==i] = k以下是每个阶段的图像。

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59765277
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号