
AWS弹性搜索集群磁盘空间在数据实例之间不平衡
背景
我有一个AWS托管Elascsev6.0集群,它有14个数据实例。
它有基于时间的指数,如data-2010-01、...、data-2020-01。
问题
不同实例之间的空闲存储空间非常不平衡,我在AWS控制台中可以看到:
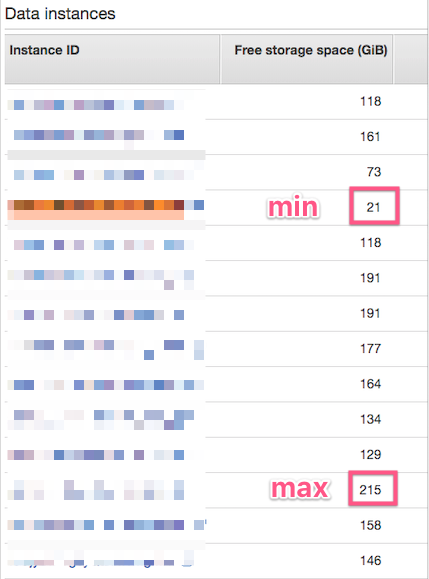
我注意到,每当AWS服务通过蓝绿色部署运行时,这个发行版就会发生变化。当更改群集设置或AWS发布更新时,就会发生这种情况。
有时,蓝绿色会导致其中一个实例完全耗尽空间。当这种情况发生时,AWS服务将启动另一个蓝绿色的服务,这解决了不影响客户的问题。(这确实影响了我的心率!)
碎片尺寸
我们的索引的碎片大小是千兆字节大小,但低于弹性搜索推荐 of 50GB。不过,碎片的大小根据索引的不同而不同。我们的许多旧指数只有少数几份文件。
问题
AWS平衡算法不能很好地平衡,而且每次都会产生不同的结果,这是出乎意料的。
我的问题是,算法如何选择将哪些碎片分配给哪个实例,以及我自己如何解决这种不平衡?
回答 1
Stack Overflow用户
发布于 2020-01-09 03:41:39
我问了这个AWS支持的问题,他们给了我一个很好的答案,所以我想在这里和其他人分享一下总结。
简言之:
- AWS基于碎片计数而不是碎片大小分发碎片,因此,如果可能的话,保持碎片大小的平衡。
- 如果将集群配置为跨3可用性区域分布,则使数据实例计算一个可被3除除的。
My Case
我的14个实例中的每一个都得到~100 shards而不是~100 GB。
记住,我有很多相对空洞的指数。这转化为小碎片和大碎片的混合,在AWS弹性搜索(无意中)将大量大碎片分配给实例时,这会导致不平衡。
更糟糕的是,我已经将集群设置为跨3个可用性区域分发,而数据实例计数(14)不能被3整除。
将我的数据实例计数增加到15 (或减少到12)解决了这个问题。
来自多AZ上的AWS弹性搜索文档:
为了避免这种可能导致单个节点紧张并影响性能的情况,如果计划每个索引有两个或多个副本,建议您选择一个实例计数为三个的倍数。
进一步改进
除了可用性区域问题之外,我建议保持索引大小的平衡,以使AWS算法更容易。
在我的例子中,我可以合并旧的索引,例如data-2019-01 . data-2019-12 -> data-2019。
https://stackoverflow.com/questions/59656928
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号