
自动编码器学习所有样本的平均值
我是一个编程爱好者,学习如何从头开始编写一个自动编码器。我已经尝试过用简单的神经网络来处理线性回归问题和非线性数据分类,所以我认为这并不难。我的自动编码器知道它是最好的,但是输出是所有输入的平均值,就像这两个:
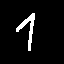

这是输出:

如果你想看一段关于it训练的视频,它在这里:https://youtu.be/w8mPVj_lQWI
如果我把所有其他17个样本(另一批数字1和2)加在一起,它也会变成涂片、平均外观结果:
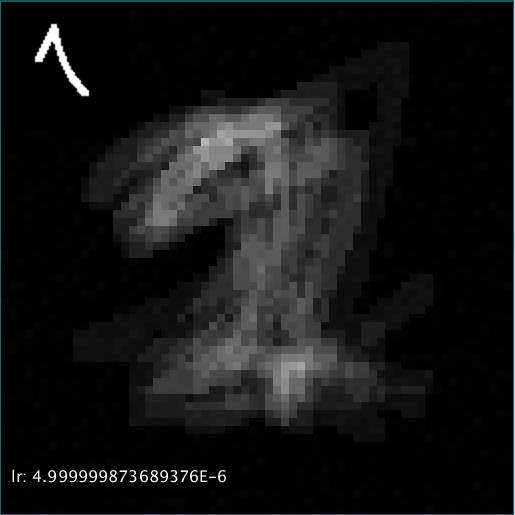
我把我的网络设计成3层,有64个输入神经元(输入是一个4096维向量,参考64x64图像样本),瓶颈部分(第二层)有8个神经元,输出4096个神经元,每一个都是最终输出的一维。
我使用tanh作为我的激活函数(除了最后一层,它使用线性激活)和反向传播作为学习算法,计算来自输出层神经元的偏导数,返回到输入神经元。
左上角是输入图像,中间是输出图像。所有值从-1到1(因为tanh激活),其中1表示白色,0及以下表示黑色。
输出图像是在2幅图像的12k周期后产生的,即学习速率为5*10-e6。
一个有趣的发现是,如果我将学习率提高到0.001,输出就会明显地变成1或2,但是顺序是错误的。看一看这个视频:https://youtu.be/LyugJx8RiJ8
我可以尝试用5层神经网络进行训练,但它也是这样做的。
你能想到我写的代码可能会有什么问题吗?我没有使用任何现成的库,从零开始的一切,读取像素和其他东西。这是我处理的代码,如果有帮助的话(尽管它非常麻烦):
class Nevron{
public double w[];
public double a;
public double z;
public double b;
public double der;
public double derW;
public double derB;
public double lr = 0.00001;
public Nevron(int stVhodov){
w = new double[stVhodov];
a = 0;
z = 0;
der = 0;
for(int i = 0; i < w.length; i++){
w[i] = random(-1, 1);
}
b = random(-1, 1);
}
public void answer(double []x){
a = 0;
z = 0;
for(int i = 0; i < x.length; i++){
z = z + x[i]*w[i];
}
z += b;
a = Math.tanh(z);
}
public void answer(layer l){
a = 0;
z = 0;
for(int i = 0; i < l.nevron.length; i++){
z = z + l.nevron[i].a*w[i];
}
z += b;
a = Math.tanh(z);
}
public void answerOut(layer l){
a = 0;
z = 0;
for(int i = 0; i < l.nevron.length; i++){
z = z + l.nevron[i].a*w[i];
}
z += b;
a = z;
}
public void changeWeight(layer l){
for(int i = 0; i < l.nevron.length; i++){
w[i] = w[i] - der * lr * l.nevron[i].a;
b = b - der * lr;
}
der = 0;
}
public void changeWeight(double []x){
for(int i = 0; i < x.length; i++){
w[i] = w[i] - der * lr * x[i];
b = b - der * lr;
}
der = 0;
}
public double MSE(double odg){
return (odg-a)*(odg-a);
}
public double derOut(double odg, double wl){
der = 2*(a-odg);
return 2*(a-odg)* wl;
}
public double derHid(double wl){
return der * (1-Math.pow(Math.tanh(z), 2)) * wl;
}
}
class layer{
public Nevron nevron[];
public layer(int stNevronov, int stVhodov){
nevron = new Nevron[stNevronov];
for(int i = 0; i < stNevronov; i++){
nevron[i] = new Nevron(stVhodov);
}
}
public void answer(double []x){
for(int i = 0; i < nevron.length; i++){
nevron[i].answer(x);
}
}
public void answer(layer l){
for(int i = 0; i < nevron.length; i++){
nevron[i].answer(l);
}
}
public void answerOut(layer l){
for(int i = 0; i < nevron.length; i++){
nevron[i].answerOut(l);
}
}
public double[] allanswers(){
double answerOut[] = new double[nevron.length];
for(int i = 0; i < nevron.length; i++){
answerOut[i] = nevron[i].a;
}
return answerOut;
}
}
class Perceptron{
public layer layer[];
public double mse = 0;
public Perceptron(int stVhodov, int []layeri){
layer = new layer[layeri.length];
layer[0] = new layer(layeri[0], stVhodov);
for(int i = 1; i < layeri.length; i++){
layer[i] = new layer(layeri[i], layeri[i-1]);
}
}
public double [] answer(double []x){
layer[0].answer(x);
for(int i = 1; i < layer.length-1; i++){
layer[i].answer(layer[i-1]);
}
layer[layer.length-1].answerOut(layer[layer.length-2]);
return layer[layer.length-1].allanswers();
}
public void backprop(double ans[]){
mse = 0;
//hid-out calculate derivatives
for(int i = 0; i < layer[layer.length-1].nevron.length; i++){
for(int j = 0; j < layer[layer.length-2].nevron.length; j++){
layer[layer.length-2].nevron[j].der += layer[layer.length-1].nevron[i].derOut(ans[i], layer[layer.length-1].nevron[i].w[j]);
mse += layer[layer.length-1].nevron[i].MSE(ans[i]);
}
}
//hid - hid && inp - hid calculate derivatives
//println(mse);
for(int i = layer.length-2; i > 0; i--){
for(int j = 0; j < layer[i].nevron.length-1; j++){
for(int k = 0; k < layer[i-1].nevron.length; k++){
layer[i-1].nevron[k].der += layer[i].nevron[j].derHid(layer[i].nevron[j].w[k]);
}
}
}
//hid-out change weights
for(int i = layer.length-1; i > 0; i--){
for(int j = 0; j < layer[i].nevron.length; j++){
layer[i].nevron[j].changeWeight(layer[i-1]);
}
}
//hid-out change weights
for(int i = 0; i < layer[0].nevron.length; i++){
layer[0].nevron[i].changeWeight(ans);
}
}
}我会感谢你的帮助。
回答 2
Stack Overflow用户
发布于 2020-01-03 22:53:59
最后,我花了大部分时间找出参数的最佳组合,并发现:
不要着急,慢慢来,看看NN是如何丢失的,它是如何下降的,如果它来回反弹,降低学习率或尝试再次运行NN (因为局部极小),progressing
- Watch
- 从2个样本开始,看看瓶颈层需要多少神经元。尝试使用圆形和正方形的图像作为训练数据,
,
- ,用神经网络更长的时间来区分相似的图像,
,
- ,然后尝试采集3个样本,看看神经元和层的最佳组合。
总之,大部分都是基于运气的(尽管在第三次尝试中仍然有很好的机会获得良好的培训),也就是说,如果您是从零开始实现它的话。我相信还有其他的方法,可以帮助神经网络跳出局部极小值,不同的梯度下降等等。这是我的自动编码器的最后结果(包含16,8,8,16,4096个神经元的5层),它可以编码Ariana Grande,Tom和Sabre的脸(来源: famousbirthdays.com)。上面的图像当然是重建我的解码器生成的。

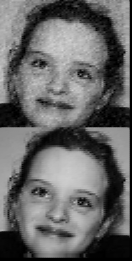

我还做了一个简单的编辑器,您可以在这里处理解码器的输入,并设法让Stephen Fry面对:

再次感谢你的帮助!
Stack Overflow用户
发布于 2021-03-19 11:37:09
我今天也遇到了同样的问题。我的解决方案其实很简单。标准化您的数据集有关的函数,例如,如果sigmoid,将输入数据缩放到范围(1和0)。这会自动解决你的问题。例如,
input = (1/255) * pixel_image_value在这里,pixel_image_value在0 -255的范围内,然后在得到输出x_hat后,在显示为图像之前将其缩放。
output_pixel_value = 255 * sigmoid_ouput_valuehttps://stackoverflow.com/questions/59577706
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号