
使用表单识别器解析内容错误
在试图分析作为架构图的PDF文件时,我收到了以下错误:
{
"error": {
"code": "2018",
"innerError": {
"requestId": "7ffbbd94-fab5-4200-b32c-990d6029a1cc"
},
"message": "Content parsing error."
}
}我正在使用表单Recognizer,PDF文件上有文本和绘图符号。我也尝试过不同的内容类型的标题(“多部分/表单-数据”,“应用程序/pdf”),具有相同的结果。如果我截图PDF文件(只有一页),并将其保存为图像,它将成功地处理。
表单识别器支持这些类型的PDF文件吗?我想知道我是不是遗漏了什么,或者建筑图纸目前不受支持。
编辑:我已经附上了两个示例绘图文件,我正在处理(混淆识别信息)。资料传奇文件是我需要从其中提取信息的主要文件。对于楼层计划文件,我只想提取关键说明部分的信息。
进一步澄清我需要提取的数据:我需要计算检测到的关键术语/短语的实例。例如,我需要扫描一个文件,看看它有多少次有文本‘洗手间’在其中。我同意表单识别器将它所看到的放在结果的记号部分。
材料图例
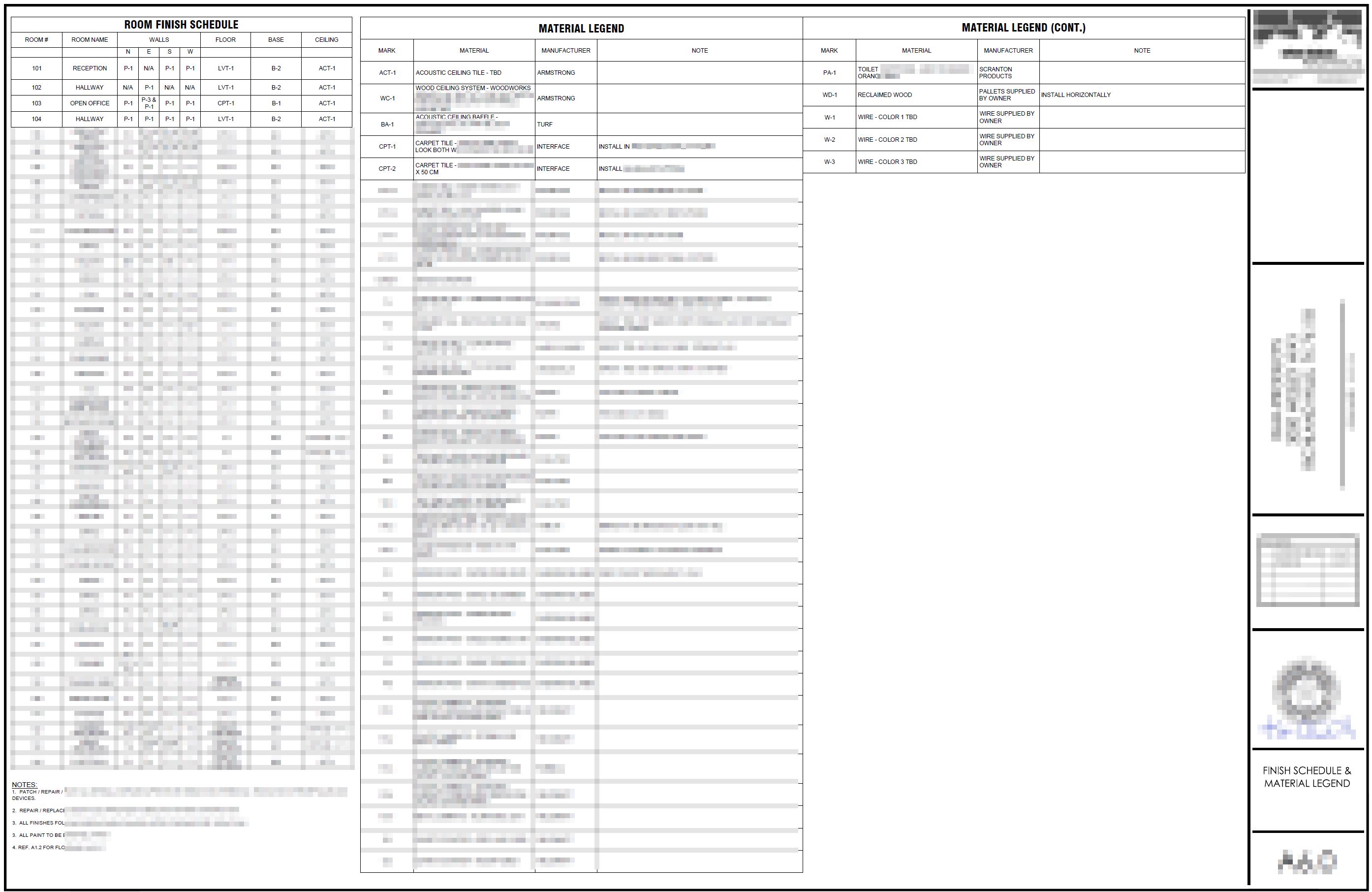
平面图示例

回答 2
Stack Overflow用户
发布于 2019-12-16 01:06:40
表单识别器主要关注有文本和值的表单(采购订单、纳税表单)。它将从文档中提取密钥/值对(地址、名称、ID)。你想从建筑图纸中得到什么类型的信息?如果您可以显示一个典型的架构图(在公共域中没有私有信息的类似的绘图),以及您的预期结果,表单识别器团队可以对此进行研究。
希望这能有所帮助。谢谢-鑫-MSFT
Stack Overflow用户
发布于 2020-06-10 10:53:07
考虑使用OCR表格工具或FOTT网站从OCR github站点培训一个模型:“要通过完整的标签-列车分析场景,您需要一组至少六种相同类型的表单。您将标记五个表单来训练一个模型,还有一个表单来测试模型。”
该模型为从表单和json映射中提取焦点提供了一些场景分析支持。
如果您还没有这样做,请尝试通过他们的表单识别器API v2进行测试。
https://stackoverflow.com/questions/59349100
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号