
在Matlab下采样矢量时如何消除偏差
在Matlab下采样矢量时如何消除偏差
提问于 2019-11-28 12:24:09
我有一组向量,包含一些任意形状,就像一个三角形脉冲,有一个最大值。我需要用整数因子对这些向量进行降采样。最大值相对于向量长度的位置应该保持不变。
下面的代码显示,当我这样做的时候,有一个由下采样步骤引入的bias=-0.0085,它的平均值应该是零。
偏差似乎变化不大,取决于向量的数量(尝试在200到800矢量之间)。
我还尝试了不同的重采样函数,如downsample和decimate,得到了相同的结果。
datapoints = zeros(1000,800);
for ii = 1:size(datapoints,2)
datapoints(ii:ii+18,ii) = [1:10,9:-1:1];
end
%downsample each column of the data
datapoints_downsampled = datapoints(1:10:end,:);
[~,maxinds_downsampled] = max(datapoints_downsampled);
[~,maxinds] = max(datapoints);
%bias needs to be zero
bias = mean(maxinds/size(datapoints,1)-maxinds_downsampled/size(datapoints_downsampled,1))
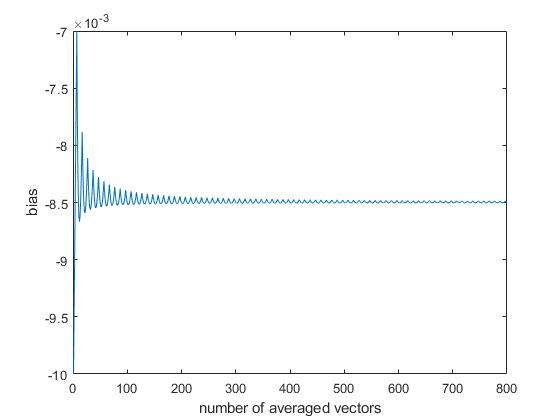
这个图表表明,系统的偏差并不取决于向量的数量。
如何消除这种偏见?是否有一种方法可以确定它的大小,只给一个矢量?
它从哪里来的?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-11-28 16:48:19
守则有两个主要问题:
- 将索引除以向量的长度导致一个小偏差:如果最大值位于第一个元素,则1/1000与1/100不相同,尽管次采样保留了包含最大值的元素。这需要修正,在除法前减去1,然后在division.
- Subsampling后加1/1000,乘以10,也会产生偏差:由于我们只确定整数位置,在1/10的情况下,我们保留位置,4/10的情况下,我们向一个方向移动位置,在5/10的情况下,我们将位置移向另一个方向。解决方案是使用奇数次抽样因子,或用次采样精度确定最大值的位置(这需要在重采样之前进行适当的低通滤波)。
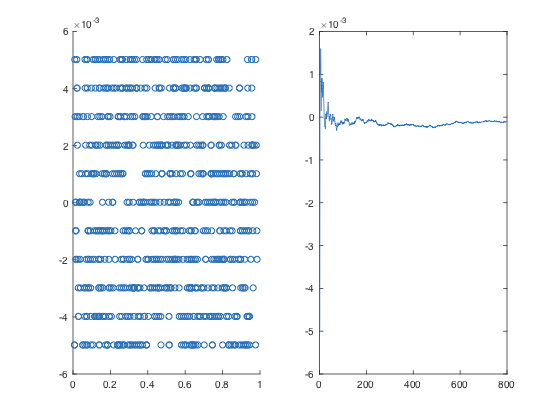
下面的代码是对OP中代码的修改,它做了错误与位置之间的散点图,以及OP的偏置图。第一幅图帮助识别上面的问题#2。我已经做了次抽样因子和次抽样变量的偏移量,我建议您使用这些值来了解正在发生的事情。我也做了最大随机的位置,以避免抽样偏差。注意,我还使用了N/factor而不是size(datapoints_downsampled,1)。如果N/factor不是整数,则下采样向量的大小是要使用的错误值。
N = 1000;
datapoints = zeros(N,800);
for ii = 1:size(datapoints,2)
datapoints(randi(N-20)+(1:19),ii) = [1:10,9:-1:1];
end
factor = 11;
offset = round(factor/2);
datapoints_downsampled = datapoints(offset:factor:end,:);
[~,maxinds_downsampled] = max(datapoints_downsampled,[],1);
[~,maxinds] = max(datapoints,[],1);
maxpos_downsampled = (maxinds_downsampled-1)/(N/factor) + offset/N;
maxpos = (maxinds)/N;
subplot(121), scatter(maxpos,maxpos_downsampled-maxpos)
bias = cumsum(maxpos_downsampled-maxpos)./(1:size(datapoints,2));
subplot(122), plot(bias)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59088846
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号