
从mdf读取时没有对齐时间戳(python,asammdf)
当我从带有asammdf (Python3.7)的mdf (.mf4)文件中读取时,当示例计数越过一个障碍时,时间戳就开始从接近0开始计数,就像溢出一样:3个文件正好在29045行,一个文件在27234行,因为某种原因。这意味着当我使用像resample或to_dataframe这样的方法时,在这些方法中发生的插值会非常糟糕,我会得到糟糕的数据。
我在文档中没有找到类似的东西,除了文档之外几乎没有任何资源。我认为这可能与块大小或内存分配有关,但我不知道如何进行不同的操作,以及为什么会发生这种情况。
现在,我通过标准方法阅读它。
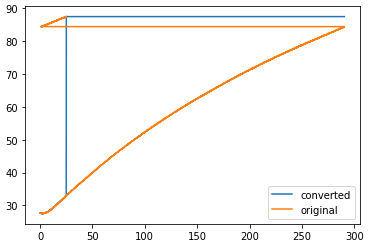
mdf = MDF(file)我编写了一个小脚本来读取文件,并绘制转换(内插的)数据与原始数据点之间的区别,以展示我的意思:
import tkinter as tk
from tkinter import filedialog as fd
from asammdf import MDF
from matplotlib import pyplot as plt
typeStr = '*.mf4'
root = tk.Tk()
root.wm_attributes('-topmost', 1)
root.withdraw()
files = fd.askopenfilenames(parent=root,filetypes=[("Measurement MF4 file",typeStr)])
for file in files:
mdf = MDF(file)
# conversion to pandas
data = mdf.to_dataframe()
data['Time [s]'] = list(data.index)
columns = data.columns.tolist()
columns.remove('Time [s]')
columns.insert(0,'Time [s]')
data = data[columns]
plt.plot(data['Time [s]'], data[columns[1]],label="converted")
# original data
chData = mdf.get(columns[1])
plt.plot(chData.timestamps, chData.samples, label="original")
plt.legend()
plt.show()这里可以访问一个示例文件:
情节的一个例子:
回答 2
Stack Overflow用户
发布于 2019-12-04 15:10:19
我发现问题实际上是由asammdf库引起的(不知怎么的)。我不能真正指出是哪个版本导致了这个问题,因为我更新了所有的库--然后它就开始工作了。目前我运行的是5.13.13版本,没有再正确读取时间戳的问题了。
编辑:不幸的是,事实证明这不是真的。我怀疑录制程序(来自AVL的PUMA测试平台软件),但我不确定在任何方面。我现在使用的是一个解决方案,我正在将一个新的全局时间戳拼接在一起,然后插入沿着这个方向的所有通道。它比库函数慢,但至少它消除了错误。
Stack Overflow用户
发布于 2019-11-20 15:23:59
谢谢你的例子文件,我会看看它。你总是可以在github回购中提出一个问题
编辑:由于时间通道不单调增加,文件已损坏,在样本索引29045处重置。
>>> ch.timestamps[29040:29050]
array([290.47998, 290.48998, 290.49998, 290.50998, 290.51998, 290.52998,
0.87998, 0.88998, 0.89998, 0.90998])最初记录这个文件的应用程序是什么?
https://stackoverflow.com/questions/58956679
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号